套裝軟體 vs OpenSource — 企業資料平台路線整體評估
以「六階段角色框架」對標三條路線,並給出一條保留性價比與擴充性的階段演進路線。
這份評估為誰而寫
- 中大型製造/傳產企業
- 有地端部署需求、資料以內部系統(ERP、生管、現場)為主
- IT 團隊具應用系統開發與 SQL 基礎
- 尚未建立資料倉庫、過往以採購套裝軟體為主
- 長期目標是 BI 與 AI 應用
若多數條件符合,本報告結論可直接適用;條件不同(如已有成熟倉庫),各章標示了判讀會如何改變。
02 / 58本報告要回答的三個問題
其實只有兩條路:買套裝,還是自建開源
套裝軟體(買現成的)
市面產品眾多,多按模組/年計價、能力綁廠商:
- 資料整合(ETL):Informatica、Talend、SSIS、Fivetran、FineDataLink
- 資料虛擬化:Denodo、TIBCO、IBM、SAP HANA
- BI/報表:FineBI、Power BI、Tableau
開源自建(自己組)
一套完整平台、零授權費、能力與資料都留在團隊:
- Airflow · PostgreSQL · dbt · Iceberg · Trino · Grafana
- 六階段一次覆蓋,任一元件可單獨替換
- 資料以開放格式存放,永不被鎖定
差別不在「哪個產品功能多」,而在「買斷當下需求」還是「累積帶得走的資產」。
04 / 58一句話定位:買工具,還是建平台
套裝軟體:一件件買的工具
搬運工具、查詢窗口、報表機——各自獨立產品、各自計價。買到的是單點功能,不是一座平台; 要拼成完整資料平台,得買好幾套、再自己接起來。
開源自建:一座完整的資料工廠
從進料到出貨,六個工站一次到位。零授權費,能力與資料都留在自己手上, 任一工站不合用都能單獨替換。
六維度綜合評估:套裝 vs 開源
| 維度 | 套裝軟體(商用) | 開源自建 |
|---|---|---|
| 六階段角色覆蓋 | 單一產品只覆蓋一兩格,需多套拼湊 | 完整,六階段一次到位 |
| 地端部署 | 可 | 可(全開源) |
| 授權成本結構 | 授權/年訂閱,依模組與用量計價 | 零授權費,投資在人與顧問 |
| 團隊能力累積 | 操作技能,綁定廠商 | 業界通用技能,留在團隊 |
| 擴充性/退場彈性 | 中低(私有格式、生態綁定) | 高(開放格式、逐件可換) |
| AI 整合自由度 | 受產品藍圖限制 | 完全開放 |
「套裝軟體」涵蓋商用 ETL、資料虛擬化與 BI 等各類產品(細部對標見第 5 章)。
06 / 58開源自建 + 三階段演進
每階段都有可觀察的觸發條件,且前一階段資產全數延續,不走回頭路。
07 / 58團隊培養
從點對點串接到統一資料層
沒有統一資料層的四個徵狀
- 點對點串接蔓延:每條需求一支客製 Job,沒人畫得出全貌
- 欄位定義各說各話:同一個「數量」「日期」各系統口徑不同
- 報表需求壓在 IT 身上:每個新報表都是一次客製開發
- AI 無從談起:資料散落各處,任何 AI 專案都卡在第一步
OLTP vs OLAP:兩種設計目標
| OLTP 交易處理 | OLAP 分析處理 | |
|---|---|---|
| 誰在用 | ERP、生管、現場系統 | 報表、看板、趨勢分析、AI |
| 典型操作 | 大量小筆讀寫 | 少量大範圍掃描彙總 |
| 設計重點 | 單筆即時、正確、不能停 | 大量掃描快、彙總快 |
| 資料保留 | 通常只留近期 | 長年累積,歷史就是價值 |
在 OLTP 上跑分析的三個後果
為什麼「買套裝軟體」在資料這件事上失靈
- 需求明確 → 選一套功能符合的
- 廠商導入 → 上線使用
- 流程固定的系統行之有年
- 資料需求是長出來的,不是定義出來的——每次成長都是一次加購
- 價值在累積:十年生產資料是資產,鎖進私有格式換廠商成本複利成長
評估對象與三步方法
- 路線一|商用套裝(低代碼資料整合):Informatica、Talend、Microsoft SSIS、Fivetran、FineDataLink 等——本報告以 FineDataLink 為代表
- 路線二|資料虛擬化:TIBCO Data Virtualization、IBM Cloud Pak for Data、SAP HANA、Dremio、Denodo 等——本報告以 Denodo 為代表
- 路線三|開源自建:Airflow / PostgreSQL / dbt / Iceberg / Trino + 顧問導入
每日各課別產出看板,資料怎麼來
六階段角色(用工廠比喻)
| 階段 | 工廠比喻 | 白話 |
|---|---|---|
| 1 Sources 來源 | 上游供應商 | 資料的產地:ERP、生管、現場、檔案、感測器(只盤點不選型) |
| 2 Ingestion 擷取 | 進貨物流 | 定時/即時把資料搬進平台,重點是穩定、自動、不漏 |
| 3 Storage 儲存 | 中央倉庫 | 資料集中的家,決定容量、成本、格式是否開放 |
| 4 Transform 轉換 | 加工產線 | 清洗、對齊口徑、彙總成可用的成品表 |
| 5 Query 查詢 | 出貨窗口 | 讓人與系統用 SQL 取數的引擎 |
| 6 Consumption 應用 | 客戶端 | BI 看板、報表、自然語言問答、AI 模型 |
貫穿所有階段的支撐角色
Orchestration 排程
生管排程:誰先誰後、失敗怎麼辦。代表:Apache Airflow。
Governance 治理
品保 + 文管:口徑一致、權限、血緣、變更紀錄(git 版控為基礎)。
Observability 監控
戰情室:排程有沒有失敗、資料量異常、磁碟夠不夠。
資料平台六階段角色框架
另有 Orchestration / Governance / Observability 三橫切面貫穿全部。這張框架是後面所有比較的尺。
18 / 58ETL vs ELT:先加工再進倉,或先進倉再加工
- 先載入、再轉換
- 原始資料完整保留,隨時可回頭重算
- 轉換邏輯是倉庫裡的 SQL 檔(可版控、可審核)
- 代表:dbt + 任一倉庫,Lakehouse 標準做法
- 先轉換、再載入
- 原始資料不保留(只留成品)
- 轉換邏輯在 ETL 工具裡(常為圖形化)
- 代表:Informatica、SSIS、FineDataLink
資料儲存架構的四個世代
Lakehouse = 在便宜儲存上加一層「表格式」(如 Apache Iceberg)。這是第 5 章目標藍圖的依據。
20 / 58用框架重新理解「為什麼選型會混亂」
- 行銷詞彙高度重疊:資料中台、數據集成、Data Fabric、一站式平台
- 有的產品只做一格(如 Denodo 專注查詢層)
- 有的做兩三格(如 FineDataLink 做擷取 + 轉換 + API)
- 有的「平台」其實是一個產品家族,每格各自計價(帆軟全家桶)
- 開源路線則是每格挑一個最成熟的元件,組成完整平台
為什麼 FineDataLink 與 Denodo 難直接比
更關鍵的是,兩者都沒回答「資料的家在哪裡」(Storage)——而對尚未建倉的企業,這正是首要目的。
22 / 58低代碼資料整合(ETL)工具
市面同類(商用低代碼資料整合):Informatica、Talend、Microsoft SSIS、Fivetran 等。本報告以 FineDataLink 為代表——中文生態完整、台灣有在地支援。
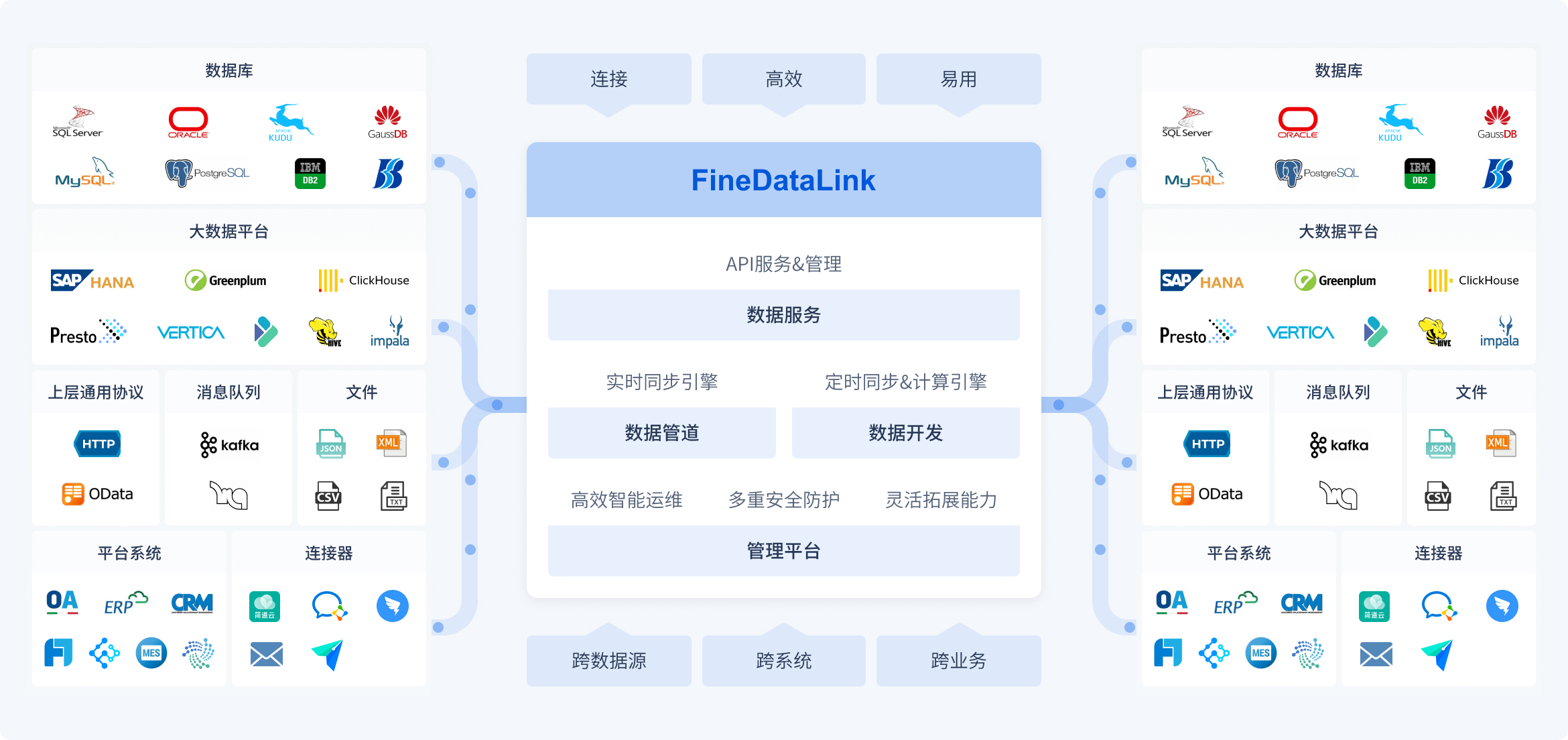
FineDataLink 官方產品架構:四個功能模組(覆蓋 Ingestion + 部分 Transform + Data API;Storage 需自備、BI 另購)。資料來源:finedatalink.com
23 / 58FineDataLink:優勢與限制
- 低代碼上手快,對沒有資料工程背景的團隊友善
- 中文生態最完整,台灣有帆軟分公司
- CDC 即時同步成熟
- 與帆軟全家桶(FineReport / FineBI)整合順
- 是工具不是平台:儲存、查詢、治理仍是空的
- 轉換邏輯存在產品內(圖形化),換工具需重建
- 授權費不公開,全家桶各自計價
- 團隊學到的是 FDL 操作,非業界通用技能
資料虛擬化(資料不落地)平台
市面同類(資料虛擬化):TIBCO Data Virtualization、IBM Cloud Pak for Data、SAP HANA、Dremio 等。本報告以 Denodo 為代表——資料虛擬化的市場領導者。
Denodo 官方架構:來源 → 資料虛擬化層 → 應用(覆蓋 Query 跨源聯邦查詢 + 語意層;不持久化、不做歷史累積)。資料來源:community.denodo.com
25 / 58Denodo:優勢與限制
- 資料不搬動——法規禁止資料外移或已有多座倉庫時的業界標準答案
- 見效快(在對的場景):接上來源就能查
- 企業級治理完整:語意層、權限、目錄、GenAI 助手
- 前提不成立:價值在整合「已存在的多座倉庫」,此情境還沒有倉庫
- 查詢壓力落在來源系統,與生產交易搶資源
- 歷史累積無解:查不到來源已清掉的歷史
- 年訂閱成本高(公開參考 NT$600–750 萬/年);專屬 VQL 人才池小
開源自建:每階段選一個最成熟的元件
| 角色 | 起步元件(Phase 1) | 目標元件(Phase 3) |
|---|---|---|
| Ingestion 擷取 | Airflow Python 任務 | Airbyte(UI、300+ 連接器) |
| Storage 儲存 | PostgreSQL | MinIO + Parquet + Iceberg |
| Transform 轉換 | dbt(SQL 模型化) | dbt(同一套,改跑 Trino) |
| Query 查詢 | PostgreSQL 本身 | Trino(分散式、可跨源) |
| Consumption 應用 | Grafana + Asgard Data Insight | + Metabase(自助分析) |
| Orchestration 排程 | Apache Airflow(全程不變) | (同左) |
| Governance 治理 | git + SQL 版控 | + OpenMetadata |
角色覆蓋矩陣:三條路線一張圖看完
| 階段角色 | FineDataLink(+FineReport/FineBI 另購) | Denodo | 開源自建 |
|---|---|---|---|
| 1 Sources | 盤點 | — | — |
| 2 Ingestion | ● 核心強項 | ○ 不搬資料 | ● Airflow / Airbyte |
| 3 Storage | ○ 需自備 | ○ 刻意不做 | ● PG → Iceberg |
| 4 Transform | ◐ 低代碼(鎖產品內) | ◐ 虛擬視圖 | ● SQL / dbt(可版控) |
| 5 Query | ○ | ● 核心強項 | ● PG → Trino |
| 6 Consumption | ◐ 需另購 | ◐ 對外供數 | ● Grafana / Metabase / ADI |
| Orchestration | ◐ 產品內 | ◐ 快取排程 | ● Airflow |
| Governance | ◐ 產品內權限 | ● 語意層/目錄 | ● git → OpenMetadata |
| Observability | ◐ 任務運維 | ◐ 平台監控 | ● Grafana / Prometheus |
● 完整覆蓋 ◐ 部分覆蓋 ○ 不覆蓋
28 / 58八個評估維度
功能覆蓋
六階段角色覆蓋程度
地端部署
可否全部署在自有機房
團隊自主維運
廠商退場後能否獨立維運
知識移轉
能力是否留在企業團隊
擴充性
資料量成長時走不走得上去
廠商鎖定
格式是否開放、退場成本
AI 整合
能否自由對接 AI 應用
成本結構
錢花在授權、硬體還是人
商用套裝路線(以 FineDataLink 為例)
| 維度 | 評估 |
|---|---|
| 功能覆蓋 | 擷取轉換強,儲存自建、BI 另購 |
| 團隊自主維運 | 易上手,但架構問題仍需原廠 |
| 知識移轉 | 產品操作,人才不流通 |
| 擴充性 | 生態內順,跨出受限 |
| 廠商鎖定 | 中高(私有格式) |
| 成本結構 | 授權費(報價制)+ 每模組計價 |
資料虛擬化路線(以 Denodo 為例)
| 維度 | 評估 |
|---|---|
| 功能覆蓋 | 查詢層世界級,但不持久化、不累積歷史 |
| 團隊自主維運 | 需 VQL 專屬技能,台灣人才池小 |
| 知識移轉 | 技能綁 Denodo |
| 擴充性 | 角色單一,資產累積仍需另建倉 |
| 廠商鎖定 | 高(VQL 私有) |
| 成本結構 | 年訂閱 NT$600–750 萬/年(公開參考) |
開源自建 + 顧問陪跑
| 維度 | 評估 |
|---|---|
| 功能覆蓋 | 六階段完整,每格皆業界主流 |
| 地端部署 | 完全地端、全開源,資料不出廠 |
| 團隊自主維運 | 以「顧問退場、團隊接手」為驗收 |
| 知識移轉 | 業界通用技能,新人可補位 |
| 廠商鎖定 | 最低(開放格式 + git 內 SQL) |
| 成本結構 | 零授權費 + 一次性導入 + 自有硬體 |
開源軟體的資安與漏洞風險
| 疑慮 | 實際情況 |
|---|---|
| 程式碼公開 = 容易被入侵? | 公開讓全球持續檢視;主流專案有正式 CVE 通報與修補,常快於商用版本週期 |
| 沒有廠商,漏洞誰修? | 元件皆有專職組織(Apache、各母公司),且都有付費商業支援可加購 |
| 有大企業在用嗎? | PostgreSQL/Airflow/Iceberg/dbt 誕生並運行於 Netflix、Airbnb 等生產環境 |
| 授權有法律風險嗎? | 多為 Apache 2.0 / MIT;少數例外(MinIO AGPL v3)導入時由顧問盤點 |
五年期成本結構量級比較
| 成本項 | 商用套裝 | Denodo | 開源自建 |
|---|---|---|---|
| 軟體授權/訂閱 | 報價制、逐模組加購 | NT$600 萬+/年,五年累計數千萬 | 0 |
| 導入/顧問 | 原廠導入(另計) | 原廠/代理(另計) | 一次性導入(依範圍議價) |
| 硬體 | 自備 | 自備 | 自備(Phase 1 一台 VM 起) |
| 團隊人力 | 操作為主 | 仰賴外部專家 | 1–3 名種子工程師(訓練後自主) |
| 五年後的處境 | 持續付授權、能力在廠商 | 持續付訂閱、能力在廠商 | 不再付授權、能力在自己團隊 |
建議路線三,濃縮成三句話
三個具體理由
資料資產的保險
資料以開放格式(Parquet + Iceberg)存在自己的儲存上,十年後任何引擎都讀得到。
一份資料、多引擎
報表、批次加工、AI 訓練用不同引擎讀同一份資料,不需複製。
成本曲線平緩
儲存用便宜物件儲存、計算依需擴充;資料成長十倍,成本不會成長十倍。
地端全開源 Lakehouse 架構
Airflow 排程、git 治理、Prometheus + Grafana 監控橫向貫穿全部元件。
37 / 58Lakehouse 的內部:五層解剖
儲存與計算徹底解耦——換引擎時,資料一個位元組都不用搬。
38 / 58各元件是誰:一句話介紹
| 元件 | 角色 | 一句話 |
|---|---|---|
| Apache Airflow | 排程(橫切面) | 業界排程標準,以 Python 定義 DAG。Airbnb 開源 |
| Airbyte | Ingestion | 300+ 連接器,UI 設定同步,內建 CDC |
| MinIO | Storage L1 | 地端 S3 相容物件儲存標準解 |
| Apache Iceberg | Storage L3 | 開放表格式,Netflix 開源;ACID、時間旅行、欄位演進 |
| dbt | Transform | SQL 轉換模型化:依賴解析、測試、血緣 |
| Trino | Query | 分散式 SQL,跨源聯邦查詢(對應 Denodo 核心能力,零授權費) |
| Metabase / Grafana | Consumption | 自助分析 / KPI 看板 + 監控 |
| Asgard Data Insight | Consumption(AI) | 自然語言查詢與 AI 分析入口 |
dbt 與 Airflow:日常維運的兩個介面
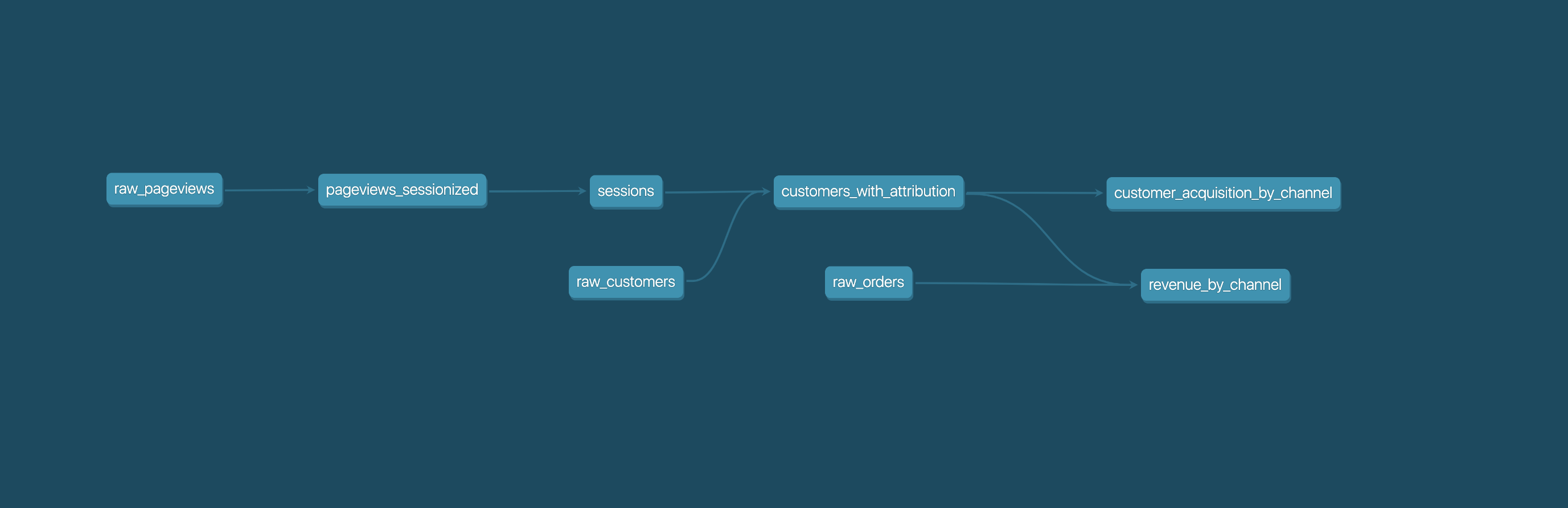
dbt 自動產生的模型依賴(血緣)圖
40 / 58架構的已知取捨與限制
| 取捨 | 因應 |
|---|---|
| 元件數量多(8–10 個) | 分階段導入,Phase 1 只有 5 個,每階段擴充有觸發條件 |
| 沒有 24×7 原廠支援 | 導入期顧問承擔,訓練以「團隊能自行排障」驗收,各元件有商業支援可加購 |
| 即時性為分鐘級 | 製造 KPI 分鐘級已足;未來秒級需求可外掛 Kafka,不動主架構 |
| MinIO 採 AGPL v3 | 企業內部使用無虞,導入時由顧問完成授權盤點,必要時可換物件儲存 |
分階段的三個理由
性價比
起步資料量 GB 級、表數十張,一台 PostgreSQL 綽綽有餘;直接上 Lakehouse 是用大砲打蚊子。
學習坡度
先在 5 個元件的小架構學會核心觀念,再逐步接觸進階元件。
風險控制
第一條業務閉環 3–4 個月見效,用成果決定下一階段投資。
每階段都是可運作的完整平台
階段之間以「觸發條件達成」推進,不是半成品。
43 / 58PostgreSQL 資料中台
- 五個核心元件,一台 VM 即可起步,以 git 版控貫穿
- 挑一條真實業務閉環(如 MES 報工 → 生管決策)跑通,但架構從第一天就通用
- 日常維運在 Airflow / Grafana / ADI 三個網頁介面完成
- 約 3–4 個月,含種子工程師訓練與結業驗收
每次升級都有可觀察的觸發條件
| 導入項 | 觸發條件 | 帶來什麼 |
|---|---|---|
| Airbyte(介接 UI 化) | 資料來源 > 5 種,或出現 SaaS/雲端來源 | 新來源從「寫程式」變「UI 點幾下」,CDC 內建 |
| OpenMetadata(資料目錄) | 非 IT 開始用中台,或表數 > 20 | 全公司可搜尋的資料目錄、欄位級血緣、變更審核 |
| MinIO + Iceberg | 資料近 TB 級、PG 掃描變慢、需長年歷史 | 成本大降、容量近乎無上限、時間旅行、開放格式 |
| Trino | 跨庫查詢、併發成長、報表變慢 | 單一 SQL 入口、水平擴充、跨源聯邦查詢(對應 Denodo,零授權費) |
資產延續對照表
| 資產 | Phase 1 | Phase 2 | Phase 3 |
|---|---|---|---|
| 三層資料模型 | 建立 | 沿用 | 沿用(搬到 Iceberg) |
| 轉換 SQL(dbt) | 建立 | 持續擴充 | 改跑 Trino,邏輯不重寫 |
| Airflow 排程 | 建立 | 沿用 | 沿用 |
| git 版控流程 | 建立 | 沿用 | 沿用 |
| 看板 / AI 查詢 | 建立 | 沿用 | 換連線目標即可 |
| 團隊能力 | 排程/建模/版控 | + 介接/資料目錄 | + Lakehouse/分散式查詢 |
簡易版起步 = 完整藍圖的第一階段
三種互補的看數據方式
| 工具 | 適合誰 | 說明 |
|---|---|---|
| Grafana | 管理層 KPI 看板、產線即時戰情 | Phase 1 即上線,固定版面、自動更新、支援告警 |
| Metabase | 業務/生管自助探索 | Phase 2/3 加入,拖拉式,不寫 SQL 也能自己拉圖表 |
| 商用 BI(選配) | 特定部門偏好 FineBI/Power BI | 開源資料層以標準 SQL 對外,任何商用 BI 都能連 |
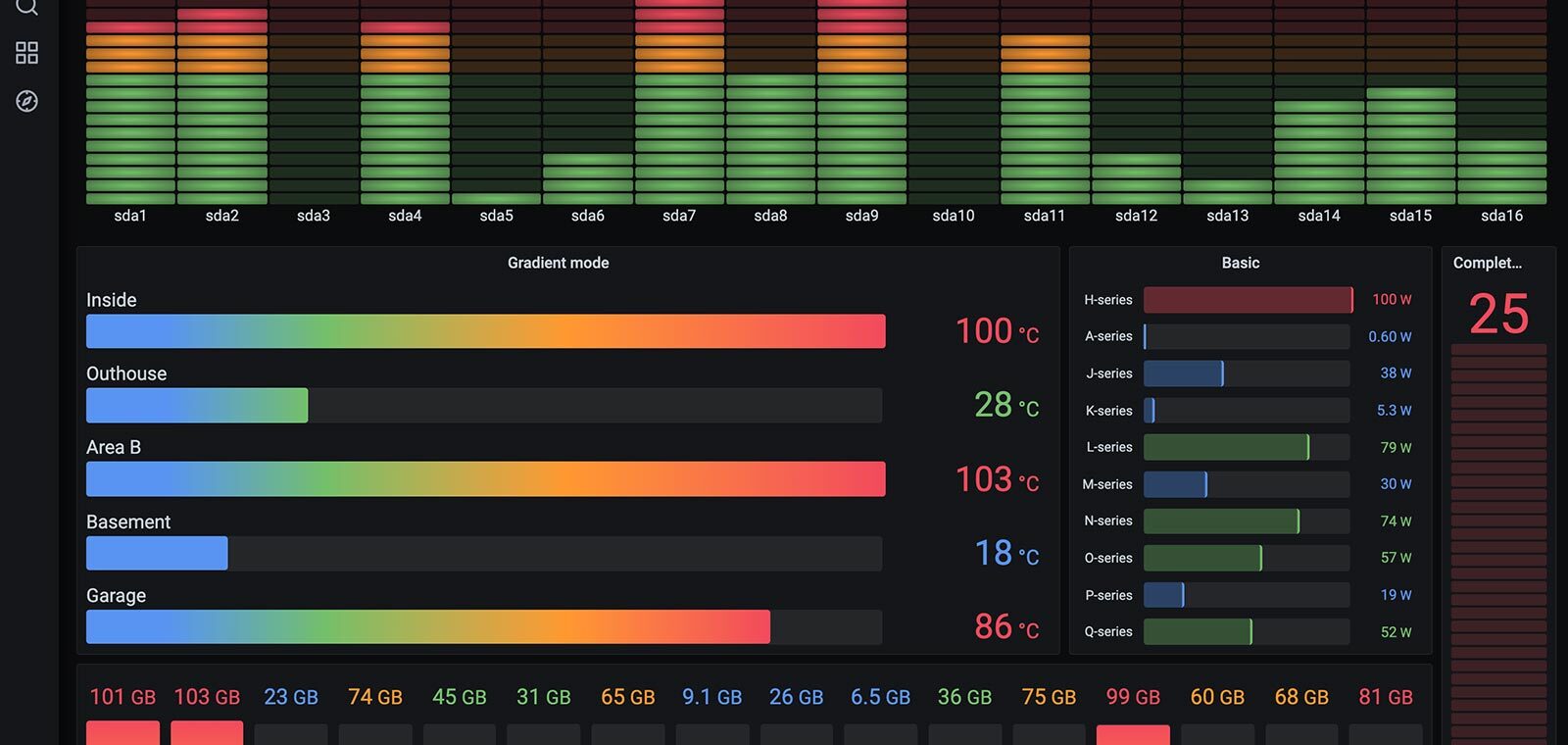
Grafana 看板:KPI、趨勢、告警集中一頁
48 / 58Asgard Data Insight:自然語言查詢
AI 問答的品質,取決於資料層的品質
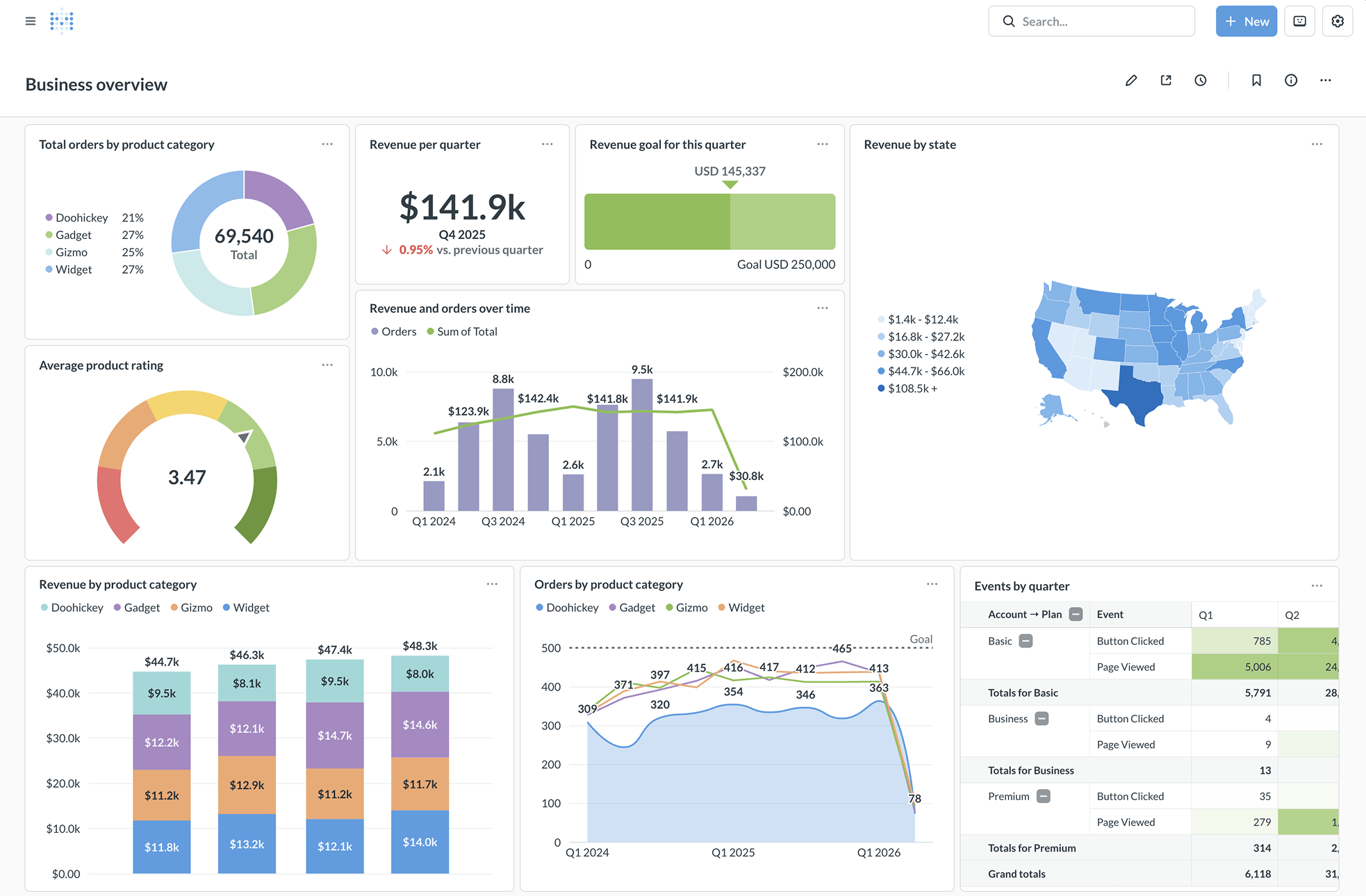
Metabase 自助分析:業務人員拖拉即可建立圖表
50 / 58資料平台上的進階 AI 應用
| AI 應用 | 回答的問題 | 需要的資料基礎 |
|---|---|---|
| 品質追溯分析 | 這批不良品與哪些機台/班別/物料批號相關? | 報工 + 品檢 + 批號關聯(1 年+) |
| 產能/交期預測 | 這張工單實際會何時完成? | 工單 + 報工 + 換線歷史(1–2 年) |
| 設備預測維護 | 哪台設備可能要出狀況? | 稼動 + 維修 + 感測器(Lakehouse 階段) |
| 排程最佳化 | 怎麼排換線最少、交期最穩? | 以上全部 + 換線規則 |
為什麼 Handover 是選型的一部分
| 商用套裝 | Denodo | 開源自建 | |
|---|---|---|---|
| 日常維運靠誰 | 自己(產品操作) | 原廠/代理為主 | 自己(訓練後) |
| 新需求擴充靠誰 | 原廠模組 + 加購 | 原廠/代理 | 自己(顧問備援) |
| 能力沉澱在哪 | 廠商生態 | 廠商生態 | 企業自己的團隊 |
| 人員流動風險 | 重招重訓(技能不流通) | 人才池小 | 技能業界通用,市場可補人 |
開源路線把「培養團隊」當成交付物的一部分——不是附贈的教育訓練,而是有驗收標準的工程交付。
52 / 58指派 2 名種子工程師,全程參與導入
不是旁聽,是動手
在顧問引導下實際建立部分資料表與排程——平台有一部分是「自己蓋的」。
訓練即工作
課綱與專案里程碑同步,學的東西當週就用在正式環境。
雙人制
避免單點依賴,互為備援與 code review 對象。
具基本 SQL / 程式經驗即可(.NET、Java 等應用開發背景完全適用)。
53 / 58六週核心課綱:跟著做 > 自己做
| 週次 | 主題 | 結業能力 |
|---|---|---|
| 1 | 中台架構 + git 版控 + PG 三層模型 | 理解三層設計、能完成版控提交與審核 |
| 2 | Airflow 入門 + 第一個排程 DAG | 能讀懂與手動操作既有排程 |
| 3 | 排程撰寫模式(冪等/增量/回補) | 能選對可重用模板 |
| 4 | dbt 模型 + schema 變更 + 資料測試 | 能新增模型、走完變更流程 |
| 5 | Grafana 看板 + ADI + 故障 SOP | 能配看板、設告警、處理常見故障 |
| 6 | 結業實作:獨立新增一張中台資料表 | 整合前五週能力,顧問僅在旁提示 |
導入結束時全數移交(存於客戶自己的 git)
| 產出物 | 內容 |
|---|---|
| 架構文件 | 整體架構圖、各元件配置、連線與權限清單 |
| 維運手冊 Runbook | 排程失敗、資料延遲、磁碟告警、備份還原 SOP |
| 資料血緣文件 | 每張表的來源、欄位、口徑、更新頻率 |
| 排程模板 | 三種可重用模式範本 |
| 訓練教材 | 六週課綱講義 + 實作演練 |
| 變更管理流程 | git 審核流程與慣例 |
團隊能力與平台架構同步演進
顧問角色從「主導」逐階段轉為「備援」。
56 / 58三個具體動作
謝謝
Asgard 肆佳科技 · 企業資料平台選型評估
肆佳科技股份有限公司