從會聊天的 AI,到能交辦工作的 Agent
一小時 workshop:先建立 AI Chat / AI Agent / 六層架構的共同語言,再拆 MCP、Skill、Sandbox、Plugin,最後用 Codex / Claude Code 與 Asgard 看如何落地。
不是學一堆術語
而是知道怎麼把 AI 從聊天工具,變成可以被委派工作的夥伴。
你會帶走一套路線圖
知道什麼時候用 chat、什麼時候需要 agent、工具如何接入、能力如何被包裝與治理。
講者介紹:WJWang
從 MIS、平台工程、LegalTech、影音串流、電商與企業數位轉型一路做到 AI agent infrastructure。今天不是只講概念,而是用真實開源 repo 與實作流程拆給大家看。
今天的主線:先有地圖,再看零件,最後看怎麼上手
為什麼不是同一件事
Model 到 Governance
MCP / Skill / Sandbox / Plugin
如何把元件組成工作循環
Claude Code / Codex / OpenClaw / Hermes
從實作回到平台化
順序刻意從大到小:先分清 chat 與 agent,再建立六層模型;接著才拆 MCP、Skill、Sandbox、Plugin;最後比較不同工具與框架,並用 demo 和 Asgard 產品生態系收束。
Agent 不是更會聊天的 chatbot,而是可以被委派工作的系統
Chat
單次問答,靠 prompt 和 context 產生回覆。
Tool-using Assistant
能查資料、呼叫 API、讀檔案,但通常仍是短任務。
Production Agent
能規劃、執行、恢復、記憶、稽核,並在權限邊界內長時間工作。
Chatbot 停在回答;production agent 要能接任一段工作。判斷標準不是語氣像不像人,而是能不能被驗收、能不能失敗後回來。
從「問 AI」到「委派 AI」差在哪裡?
把「一句需求」拆成五個工作步驟:找資料、做判斷、產出、留下紀錄。這就是 agent 和一般問答最大的差別。
先定義 agent 系統的六個技術角色
| 技術詞 | 系統角色 | 它解決的工程問題 |
|---|---|---|
| Model | 推理與生成層 | 理解輸入、規劃下一步、產生文字或 tool call |
| Tools / MCP | 外部能力介面 | 查資料、呼叫 API、取得真實系統狀態 |
| Harness | runtime / orchestration layer | 管理 agent loop、tool routing、approval、retry、stop condition |
| Sandbox | 隔離執行環境 | 讓模型產生的程式與指令在受控環境中執行 |
| Session / Memory | 狀態與事件儲存 | 保存進度、checkpoint、上下文摘要與可恢復紀錄 |
| Governance | 政策與稽核控制 | 定義誰可以讓 agent 使用什麼工具、資料與權限 |
完整 agent 應用不是單一模型呼叫,而是 model、tool interface、runtime orchestration、execution isolation、state management、governance control 的組合。
Agent 系統的六層技術架構
Policy / Audit
State
Execution
Runtime
Interfaces
Reasoning
六層分離讓模型、工具、runtime、執行環境、狀態儲存與治理政策可以各自演進;這也是 agent 從 demo 走向 production 的基本拆分。
Model 是推理層,不應承擔整個系統狀態
Stateless
不要把長期狀態都塞在一次對話裡。
Replaceable
不同任務可以換不同模型,不應該重做整個流程。
Focused
讓模型做判斷,不要讓模型自己扛流程、權限和記憶。
模型負責理解、規劃與產生 tool call;長期流程、工具選擇、權限、狀態與可恢復性應由 runtime 與系統層管理,避免把不可維護的狀態藏在 prompt 裡。
Agent 用工具的方式不只一種:先看 Tool Use 的基本面
OS / FS
直接讀檔、寫檔、列目錄、搬檔。最原始的工具呼叫,agent 在 sandbox 內就能做。
CLI tool
git、ffmpeg、grep、curl 等系統指令。很多時候直接 spawn process 就好。
HTTP / SDK
直接打 REST、GraphQL、廠商 SDK。簡單任務不必加 MCP 一層。
子流程
跑 script、launch app、開啟 sandbox 內的 service 並監聽輸出。
Tool use 的本質是「呼叫外部能力」。MCP 是其中一種協議——一種「把工具的 schema、權限、錯誤格式做給 AI 看」的標準。下一頁開始拆 MCP;後面再對照 CLI 與 A2A,看它們各自的位置。
MCP 是 AI 應用與外部系統之間的標準協定
MCP 定義 client-host-server 架構與 resources、tools、prompts 等 primitives;它的價值在於標準化工具發現、參數 schema、回傳格式、錯誤處理與權限邊界。
MCP、CLI、A2A 是 tool use 的三個並列方向,不是上下層
| 協議方向 | 連接什麼 | 為什麼選它 |
|---|---|---|
| MCP 對下:標準化工具 | 把資料源 / 工具 / 服務包成 AI 看得懂的 schema | 需要 governance、多 client 共用、tool discovery、權限與錯誤格式統一時。 |
| CLI / SDK 對自己:直接呼叫 | git、ffmpeg、curl、廠商 SDK、本機 script | 本機任務、輕量整合、原型階段;不需要對外 expose schema 時最快。 |
| A2A 對側:agent 之間 | 另一個 agent runtime(自家 sub-agent 或外部 agent) | 任務委派、長流程拆分、跨 runtime 協作;適合多 agent 編排場景。 |
三個方向沒有「正確答案」。同一個任務裡可能同時用 MCP(查實價登錄)+ CLI(git commit)+ A2A(把生成簡報的子任務委派給另一個 agent)。Harness 的責任就是知道何時用哪一個。
Harness 是 agent runtime 與 orchestration layer
管理整個工作循環
Harness 管理 agent loop:將模型輸出轉成 tool call,執行後把結果回填給模型,並處理 routing、approval、retry、checkpoint、trace 與 stop condition。
Harness 是什麼?
不是 prompt
Prompt 是一次要說什麼;harness 是整段流程怎麼跑。
不是 tool use
Tool use 是一次呼叫;harness 管呼叫前後的判斷、重試與停止條件。
不是 model
Model 做推理;harness 把推理包進可恢復的工作系統。
Prompt 是單次輸入與指令;tool use 是一次外部動作;harness 是管理多步驟 agent run 的 runtime,包括狀態、工具、錯誤、權限與交付結果。
Prompt、Context、RAG、Harness 不是平行關係
Context engineering 的問題是:選擇、排序、壓縮、丟棄。
RAG ≈ 檢索;Memory ≈ session/user/task 狀態。
技術關係:prompt ⊂ context;RAG / memory 是 context supply mechanisms;harness 是管理 context、tools、state、policy 的 agent runtime。
一張圖看完整 agent 系統:不是一個模型,而是一組可控資產
Plugin、skill、workflow、MCP、CLI 都應被視為可治理的 agent assets。Harness 將這些資產接入同一個 run lifecycle,提供 planning、execution、logging 與 review surface。
六層架構是地圖;接下來拆實作時會看到四種常見元件
載入、調度、權限、恢復
後半段的閱讀方式是:MCP 對應 L2 外部工具介面;Sandbox 對應 L4 執行隔離;Skill 是方法與知識資產;Plugin 是把 skills、commands、agents、hooks、MCP config 打包分發的格式。它們會被 L3 harness 接進同一個任務生命週期。
會用 MCP 不等於會設計 MCP Server
Tool description
不是 API 文件,而是告訴 AI 什麼時候用、怎麼用、什麼時候不要用。
Permission boundary
權限必須在 server 端強制,不靠 AI 自律。
Error as prompt
好的錯誤訊息會讓 AI 自我修正,壞錯誤會讓它卡住。
工具描述要寫給 agent 看:什麼時候用、不要什麼時候用、失敗後怎麼修正。權限要在 server 端強制,不靠模型自律。
MCP Server 怎麼包裝?把外部系統變成 AI 可呼叫的工具
告訴 client 怎麼啟動 server:command、args、cwd、env。團隊可放在專案,個人可放在 user scope。
例如 mcp_server.py 載入 tool modules,app.py 建立 FastMCP singleton。
每個 function 都有參數、描述、回傳格式與錯誤策略,讓 agent 知道何時使用。
mcp-tw-judgment/
├── .mcp.json # uv run mcp-tw-judgment
├── mcp_server.py # mcp.run();預設 stdio transport
├── app.py # FastMCP("mcp-tw-judgment")
└── tools/
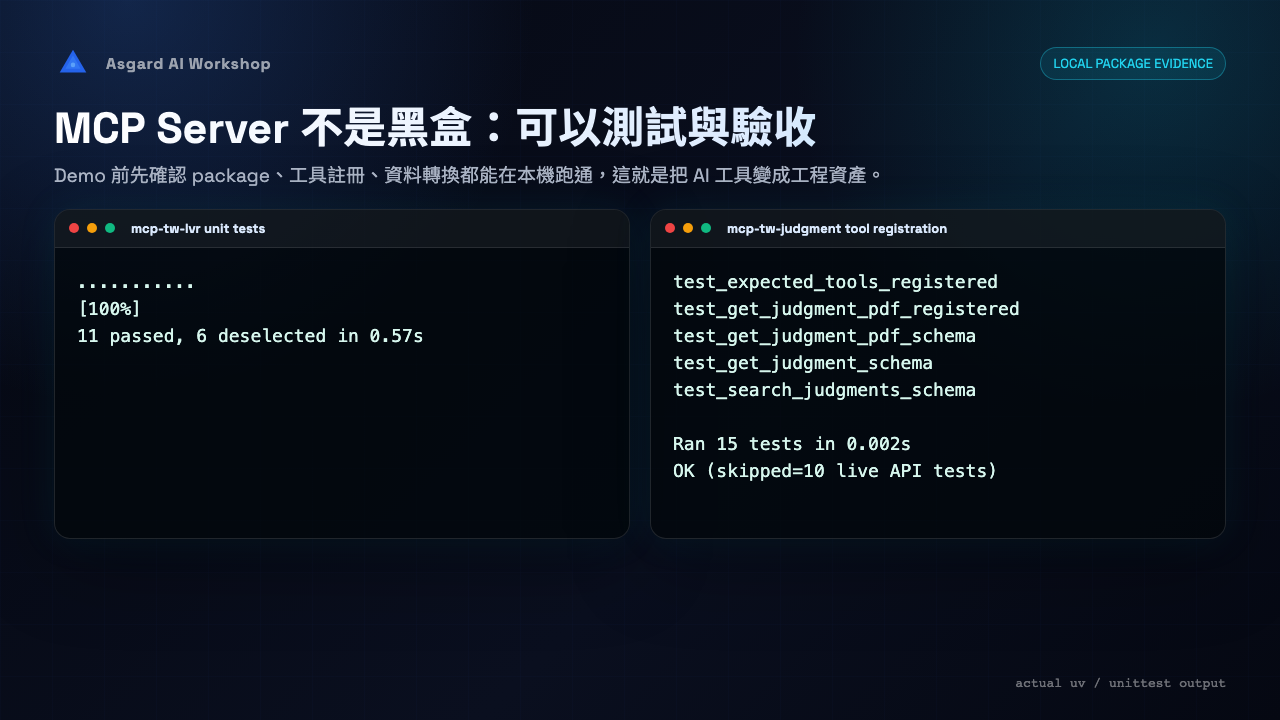
└── judgment_tools.py # search_judgments / get_judgment / get_judgment_pdfMCP server 將外部 capability 封裝成可 discovery、可 schema validation、可 invocation 的 tool interface。設計重點是 tool description、input / output schema、error semantics 與 server-side permission boundary。
.mcp.json:把工具連線方式變成專案設定
{
"mcpServers": {
"server-name": {
"type": "stdio | http | sse",
"command": "...",
"args": [],
"env": {},
"url": "...",
"headers": {},
"oauth": {}
}
}
}它不是 tool schema 本身
.mcp.json 管的是 MCP client 如何啟動或連接 server。真正的 tool name、description、input schema、output result,是 server 啟動後透過 MCP protocol 的 tools/list / tools/call 交換。
.mcp.json 不等於 tool schema:它只定義 client 怎麼連線
| 設定層 | 負責內容 | 常見錯誤 |
|---|---|---|
.mcp.json | server 名稱、transport、啟動 command、遠端 URL、env、headers、OAuth 參數 | 把敏感值直接 commit、command 路徑寫死、scope 放錯、HTTP token 寫進 repo |
| MCP server code | 工具實作、tool schema、resources、prompts、錯誤格式、權限檢查 | 工具描述太模糊、錯誤不可修正、server 端沒做 permission boundary |
| Harness / Client | 讀取設定、啟動 server、列出 tools、處理 approval、限制輸出大小、將 result 回填 context | 讓過大的 tool output 直接進 context,或沒有工具使用審核 |
.mcp.json 管「怎麼連到 server」;MCP server 管「提供哪些能力」;harness 管「何時、誰、用什麼權限呼叫」。stdio server:client 啟動本機 process
{
"mcpServers": {
"tw-lvr": {
"type": "stdio",
"command": "uv",
"args": [
"--directory",
"${PROJECT_ROOT:-.}",
"run",
"mcp-tw-lvr"
],
"env": {
"CACHE_DIR": "${HOME}/.cache/mcp-tw-lvr"
}
}
}
}| 欄位 | 用途 |
|---|---|
type | 指定 transport。stdio 代表 server 是本機子行程,透過 stdin / stdout 溝通 JSON-RPC。 |
command | 要執行的 binary 或 script,例如 node、python、uv、npx。 |
args | 傳給 command 的參數。server 自己的 flags 放這裡,不要和 client flags 混在一起。 |
env | 只傳給這個 MCP server process 的環境變數;適合放 machine-specific path 或由外部注入的 secret reference。 |
stdio 適合本機檔案、內網工具、private scripts、需要直接存取 workspace 的工具。風險是它以使用者權限執行,所以 command 來源、env、tool permission 都要被審核。
http server:連到遠端 MCP endpoint,auth 在連線層處理
{
"mcpServers": {
"internal-api": {
"type": "http",
"url": "https://mcp.internal.example.com/mcp",
"headersHelper": "/opt/bin/get-mcp-auth-headers.sh",
"oauth": {
"scopes": "read:orders write:tickets",
"callbackPort": 8080
}
}
}
}| 欄位 | 用途 |
|---|---|
url | 遠端 MCP endpoint。適合 SaaS connector、企業 API gateway 或集中管理的 shared server。 |
headers | 靜態 HTTP headers。能用,但不建議把長期 token 直接寫進版本控管。 |
headersHelper | 連線時執行 helper 產生 headers,適合短效 token、內部 SSO、Kerberos 或自家 vault。 |
oauth | OAuth client metadata、callback port、scope pinning、metadata discovery override。 |
遠端 MCP 的核心價值是把 auth、audit、rate limit、tool filtering 與多使用者治理集中化。模型仍只需要看 tool schema 與業務參數,credential 應留在 client / connector / proxy 層。
.mcp.json 可以設定什麼?重點是 transport、scope、env、auth
| 設定面向 | 可設定內容 | 實務判斷 |
|---|---|---|
| Transport | stdio、http、舊版 sse | 本機工具用 stdio;雲端與多人共用服務優先用 http;SSE 只在既有服務需要時使用。 |
| Scope | local、project、user、plugin-provided | project scope 會寫進 repo root .mcp.json,適合團隊共享;local / user 較適合個人與敏感設定。 |
| Env expansion | ${VAR}、${VAR:-default} 可用在 command、args、env、url、headers | 讓設定可版本控管,但每台機器用自己的環境變數與 secret store。 |
| Auth | headers、headersHelper、oauth.clientId、oauth.callbackPort、oauth.scopes | 正式環境優先 OAuth 或動態 headers;避免把長期 token 寫進 repo。 |
| Operational limits | MCP_TIMEOUT、MAX_MCP_OUTPUT_TOKENS、server-side max result metadata | 避免 server 啟動太慢、tool result 過大、context 被大量輸出淹沒。 |
從 .mcp.json 到 tool call:實際生命週期
mcpServerslocal / project / user
stdio process / http endpoint
tools/listresources / prompts
approval / allowlist
tools/call回填 result
這個生命週期說明了為什麼 MCP 不是單純「把 API 包起來」。它還包含設定載入、transport、capability discovery、permission boundary、tool result 管理與 context 回填。
MCP 裝在哪裡?local / project / user / remote 差別在治理邊界
| 型態 | 裝在哪裡 | 適合場景 | 主要風險 |
|---|---|---|---|
| Local / stdio | 使用者機器或專案資料夾,由 client 啟動 | 本機檔案、內網工具、開發者工具、private script | 每台機器要安裝;server 以使用者權限執行 |
| Project scope | 專案根目錄 .mcp.json | 團隊共用工具、repo 專屬資料源、可版本控管設定 | 需要信任專案設定;敏感 env 不應寫進 repo |
| User scope | 個人設定檔,跨專案可用 | 個人常用工具、跨專案 utility、私有憑證 | 不同專案間容易混用,需定期盤點 |
| Remote / HTTP | 網路上的 server 或 SaaS connector | 多使用者、OAuth、集中觀測、企業 API 與雲端服務 | 網路、身份、信任來源與權限設計更重要 |
裝在哪裡不是技術細節,而是責任邊界。Local 比較像個人工具;project scope 像團隊約定;remote connector 則開始進入身份、OAuth、audit 與服務治理。
「MCP 已死,CLI 就好」是真的嗎?階段不同,屬性也不同
本機、短任務、可讀輸出
例如跑測試、grep log、產生檔案、呼叫一段穩定 script。這時 CLI 便宜、透明、好 debug。
共享、權限、schema、遠端
當工具要跨 client、多人共享、需要型別參數、OAuth、resources / prompts、可發現性,就值得包 MCP。
先 CLI,後 MCP
先用 CLI 驗證流程;當它變成團隊會重複使用、要治理、要分發的能力,再升級成 MCP Server。
CLI 適合快速驗證、本機任務與透明除錯;MCP 適合跨 client 分發、schema contract、remote service、OAuth、tool filtering 與 audit。兩者差異包含成熟度、credential boundary、context exposure 與治理模型。
關鍵差異:模型決定要做什麼,credential 應該留在執行層
| 面向 | MCP 的典型邊界 | CLI 的典型風險與做法 |
|---|---|---|
| Auth token | Token 由 client / server / harness 在呼叫時加上,例如 HTTP Authorization header;模型不需要看到 token 本身。 | 若 command 直接含 Bearer xxx,token 會進入模型、trace、terminal history 或 log;較安全做法是用 env / secret manager 展開。 |
| Tool contract | 工具名稱、description、schema、錯誤格式可被標準化,agent 比較知道何時用、怎麼修正。 | CLI 輸入輸出通常是文字慣例,彈性高但需要更多 wrapper、parser 與錯誤約定。 |
| Governance | 適合集中做 OAuth、allowlist、tool filtering、audit、remote connector 與跨 client 分發。 | 適合本機快速驗證;要團隊治理時,需要額外規範 shell scripts、env、log 與執行權限。 |
| Context exposure | Token 不該進 LLM;但 tool result 仍可能回到模型,所以仍要做 scope、資料最小化與 redaction。 | Command、stdout、stderr、debug output 都可能被 agent 看見;安全性取決於 CLI 包裝與 sandbox policy。 |
MCP 不是自動安全層;它提供較清楚的邊界:模型看到 schema 與業務參數,credential 由 client、server、proxy 或 vault 在執行層補上。CLI 也可安全,但需要額外設計 secret handling、log redaction 與 sandbox policy。
實務判斷:不是選陣營,而是選工具要被誰管理
| 場景 | 比較適合 CLI | 比較適合 MCP |
|---|---|---|
| 個人探索 | 一次性研究、跑測試、grep log、整理本機檔案,先求快與透明。 | 暫時不必急著包;除非這個工具很快會被多個 agent 或多人共用。 |
| 團隊重複使用 | 可以先保留 CLI,但要包 wrapper、固定輸入輸出、避免 token 出現在 command 文字裡。 | 流程變成團隊資產後,就適合把 schema、description、error handling 與 permission 一起包起來。 |
| 企業系統整合 | CLI 可以做內部 automation,但治理成本會落在 shell、env、runner、log 與權限規範。 | 遠端服務、OAuth、集中 audit、tool filtering、跨 client 使用,通常更適合 MCP / connector。 |
| Harness 角度 | CLI 是便宜好用的 executor,適合 sandbox 裡的本機動作。 | MCP 是可發現、可描述、可治理的 tool interface,適合被 harness 長期調度。 |
CLI 解決「我現在怎麼把事情跑起來」;MCP 解決「這個能力如何被多個 agent、多人、企業權限與 audit 長期使用」。成熟系統通常兩個都會有。
A2A:當 agent 需要跟另一個 agent 對話的協議
對方是 agent,不是工具
MCP server 是被動的:等 agent 呼叫,回傳結果。A2A peer 是主動的:有自己的規劃、記憶、子任務。
訊息更豐富
不只 tool call + result,還有 task、status、artifact、多輪 dialogue 與長時程任務追蹤。
治理面更複雜
除了「能不能用工具」,還要管「對方是誰、它能用什麼工具、artifact 能不能信」。
Google 的 A2A protocol(2025)是目前能見度最高的提案。市面上其他做法——ACP、agent mesh、各家自家 RPC——都在指同一個方向:agent 不只跟工具講話,也要跟其他 agent 講話。
MCP 跟 A2A 都「把外部包起來」,但包的層次不同
| 維度 | MCP | A2A |
|---|---|---|
| 包什麼 | 資料源 / 工具 / 服務 (被動) | 另一個有規劃能力的 agent runtime (主動) |
| 訊息結構 | tool call + JSON result,單次或少數輪 | task / status / artifact,可能是長時程多輪 |
| 典型用例 | 查資料、呼叫 API、讀寫系統 | 委派子任務、跨組織協作、specialised sub-agent |
| Credential 邊界 | 由 MCP server 在 server 側強制 | 由 peer agent 自己管理,呼叫方只看到 result |
| 失敗模式 | tool call 錯誤、schema 不對、timeout | agent 卡住、產出不對、需要對方人為介入 |
實務上常常兩個都用:你的 research agent 透過 A2A 委派「資料查詢」給 search agent,search agent 自己再透過 MCP 呼叫各種資料源。MCP 跟 A2A 不是二選一,是兩個不同層次的工具。
什麼時候真的要用 A2A?三個典型場景
跨組織協作
你的 agent 跟另一家公司或部門的 agent 講話。對方的工具與資料對你不可見也不該可見,只交換 task + artifact。
長時程子任務
「做這份簡報」「跑這份分析」「整理這個季度報告」——把整段委派出去,狀態與進度由對方追蹤。
Specialised sub-agent
主 agent 想保留乾淨的 context;專業任務丟給領域 agent (法務、設計、研究等),回傳結果即可。
選擇 A2A 的訊號是:對方有自己的規劃能力、自己的記憶、自己的 tool inventory,你不需要也不應該知道細節。如果你只是想「用工具的標準介面」,那 MCP 就夠了。
Multi-agent 不只是「多個 agent」;它是有 topology 的
Planner ↔ Executor
一個 agent 負責拆任務、規劃;另一個負責執行 tool call。最簡單也最常用。
Hierarchical
主 agent 分配子任務給領域專業 agent(法務、設計、研究),再把結果聚合。
Swarm / Consensus
多個 agent 並行做同一題,結果用投票或加權合併。適合需要交叉驗證的判斷。
Multi-agent 帶來 coordination overhead 與更多 failure mode(loop、deadlock、cost explosion)。架構上的代價要跟分工帶來的價值評估後再做。
SKILL 怎麼包裝?它裝的是 procedural knowledge,不是外部系統
skills/meta-structured-problem/ ├── SKILL.md # frontmatter + workflow ├── references/ # 詳細理論、模板、案例 ├── examples/ # 好壞範例 └── scripts/ # 可執行輔助工具
Skill = 可觸發、可載入、可版本化的任務知識包
frontmatter 的 description 是 routing surface;body 是任務流程與決策規則;references / scripts 是按需載入或執行的支援資源。
| 資產 | 包的是什麼 | 例子 |
|---|---|---|
| Skill | 判斷準則、流程、輸出格式、常見陷阱 | MECE 問題拆解、家族企業接班、說故事技巧 |
| MCP Server | 可呼叫的外部能力與資料源 | 實價登錄、司法判決、發票、Shopline、內部 API |
| Workflow | 某類任務的執行管線 | case-study、industry-analysis、executive-pitch |
Skill 的重點:讓 agent 在正確時機載入正確方法
判斷何時要用
告訴 agent 怎麼做
需要時再補深度
給好壞範例
可執行輔助工具
固定交付格式
Skill 不是把所有知識一口氣塞給模型,而是用 progressive disclosure 管理 context budget:平常只暴露 name / description;觸發後載入 SKILL.md;真正需要深度材料或計算時,才讀 references 或執行 scripts。
SKILL.md 的 anatomy:frontmatter 決定是否觸發,body 決定怎麼做
--- name: "mkt-ab-testing" description: "Design and execute marketing A/B tests... Use when the user needs to test marketing variations... even if they say 'which version performs better'..." metadata: category: "WP-09 數位行銷" tags: ["ab-testing", "conversion"] --- # Marketing A/B Testing ## Framework ## Test Design ## Output Format ## Gotchas ## Scripts ## References
description 要寫「何時用」而不是只寫「這是什麼」
模型或 harness 通常先看到技能名稱與 description。好的 description 會包含任務場景、使用時機、常見使用者說法、不要誤觸的邊界,讓 agent 能穩定選到對的 skill。
SKILL.md 欄位拆解:每個欄位都影響 routing、permission 或 context
| 區塊 | 技術作用 | 設計要點 |
|---|---|---|
name | 唯一識別與命名空間基礎 | 短、穩定、可被 plugin 或 marketplace 管理。不要頻繁改名,否則安裝、引用、文件與使用習慣都會斷。 |
description | 自動觸發與 routing 判斷的主要訊號 | 包含 use cases、同義說法、任務邊界與風險提示。這不是市場文案,而是 agent router 的分類訊號。 |
allowed-tools | 在某些平台可預先授權 skill 常用工具 | 它通常是 approval convenience,不應被誤解成安全邊界;真正禁止工具要在 permission policy / sandbox 層做。 |
| body | 觸發後載入的操作程序 | 保留核心流程、檢查點、輸出格式與 gotchas;避免塞長篇百科,長內容應拆到 references。 |
references/ | 延後載入的深度資料 | 放理論、模板、schema、長案例;在 SKILL.md 中清楚寫明「什麼情況讀哪一份」。 |
scripts/ | 可重複、可驗算的 deterministic 執行 | 把容易算錯的邏輯交給 script,例如統計檢定、價格彈性、排名分數或文件轉檔。 |
description 是 skill 的 routing surface:寫得模糊,agent 就會選錯工具
| 寫法 | 會發生什麼 | 比較穩的寫法 |
|---|---|---|
| 只寫「A/B testing skill」 | 模型知道主題,但不知道何時觸發、是否適用 landing page、email、pricing 或 campaign。 | 寫明「設計與分析 landing page、email、ad creative、pricing 的 A/B test」,並列出使用者可能說的自然語句。 |
| 只寫「price elasticity」 | 可能和 pricing strategy、conjoint、Van Westendorp 混在一起。 | 寫明「用價格與銷量資料估需求敏感度、價格變動對 revenue 的影響」,並說明不適合 willingness-to-pay 分布時使用。 |
| 只寫「structured thinking」 | 太泛,容易被所有商業分析任務誤觸。 | 寫明「複雜、模糊問題需要 MECE issue tree、hypothesis-driven analysis、Pyramid Principle 時使用」。 |
Skill routing 的目標不是「讓技能看起來完整」,而是讓 agent 在任務進來時能判斷:這個 skill 是否應該進 context、是否要搭配其他 skill、是否需要讀 references 或跑 scripts。
Skill 用三層載入降低 context cost,也降低錯誤機率
Metadataname、description 常駐在可發現清單,用於 routing 與觸發判斷。
SKILL.md body任務流程、檢查點、輸出格式與 gotchas;觸發後才進 context。
References理論、模板、案例、schema、長文件;任務需要時才讀。
Scripts / Assets計算器、轉檔器、模板、素材;能執行或套用,不一定要全部讀入模型。
這就是 skills 和一般長 prompt 的差別:prompt 通常一次塞入;skill 則把知識拆成可發現、可觸發、可按需展開的資產。這對長任務、多人共用、版本治理尤其重要。
Asgard open-source skills 把方法論、判斷準則與 gotchas 做成可重用資產
263 skills / 21 categories
Asgard open-source skill 目前以 category prefix 分類,例如 grad-、algo-、biz-、tw-、ecom-、mkt-、ops-、law-、ux- 等。
{category}-{skill-name}/
├── SKILL.md
├── examples/
├── references/
└── scripts/| 設計原則 | 為什麼重要 | 在 Asgard/Yggdrasil 的角色 |
|---|---|---|
| 方法論可攜 | 把顧問、分析、產業與法規知識從個人腦袋變成 repo asset。 | 可被不同 plugin、workflow、persona 重新組合。 |
| 錯誤模式顯性化 | gotchas 讓 agent 避免常見誤判,例如 early stopping、omitted variable bias、非 MECE 拆解。 | 提升 domain agent 的穩定度,而不是只靠模型泛化。 |
| 計算交給 script | 統計、定價、排序等可驗算邏輯不應每次靠模型重寫。 | 把 deterministic calculation 放進 scripts,讓 agent 負責判斷與整合。 |
三個實際 skill 範例:它們不是知識百科,而是任務執行規格
| Skill | 包進去的能力 | 對 agent 的實際幫助 |
|---|---|---|
mkt-ab-testing | hypothesis、primary metric、guardrail metrics、sample size、duration、decision table、A/B test script。 | 讓 agent 不會只比較兩版文案,而是先設計實驗、定義勝負標準、提醒不要偷看結果提早停止。 |
algo-price-elasticity | point / arc elasticity、log-log regression、input validation、revenue impact JSON、sanity-check script。 | 讓 agent 把「漲價會不會傷銷量」轉成可計算的需求敏感度,並要求控制 seasonality、promotion、competitor price。 |
meta-structured-problem | MECE issue tree、hypothesis-driven analysis、Pyramid Principle、output format、常見結構錯誤。 | 讓 agent 面對模糊商業問題時先拆問題、定假設、找證據,再形成 answer-first 的建議。 |
這也是 Asgard skills 的產品價值:不是替代 MCP,也不是替代模型,而是把「應該怎麼思考與交付」標準化,讓不同 agent 在不同任務中保持一致的工作方法。
要寫好一個 Skill,先檢查六件事
Trigger precision
description 是否清楚說明何時用、同義說法、任務邊界與不適用情境?
Workflow gates
是否有階段、輸入檢查、必要資料、停下來問人的條件?
Output contract
是否定義最後要交付 markdown、JSON、表格、簡報、程式碼還是報告?
Gotchas
是否把最容易犯錯的地方寫出來,讓 agent 在執行時能自我檢查?
References
長文件是否拆到 references,並在 SKILL.md 說明何時讀哪一份?
Deterministic scripts
容易算錯、格式固定、重複執行的工作,是否有 script 或 template 支援?
Skill 的品質不在字數,而在它是否能讓 agent 更穩定地做出正確決策:何時觸發、怎麼做、怎麼檢查、怎麼交付、遇到風險怎麼停。
Skill 跟 workflow 寫好了,但 agent 在哪裡執行?
前面講完 skill 與 workflow,下一個自然問題是「這些東西到底在哪裡跑」。Sandbox 是讓 agent 真的能讀檔、跑指令、產 artifact 的地方。接下來看 sandbox agent 的概念,再看 Claude Code 怎麼把 sandbox 包進來。
Sandbox agent 是什麼?讓 AI 可以動手,但不讓它亂動
Workspace
有自己的工作資料夾,可以讀寫檔案、整理中間產物、輸出報告或簡報。
Execution
能跑 shell、測試、套件安裝、瀏覽器、自動化工具,但受到權限與 timeout 控制。
Isolation
避免直接碰主機敏感檔、憑證、未批准的網路或破壞性指令。
Approval
高風險動作可以要求人批准;企業可用 allow / deny rules 固化政策。
Traceability
保留指令、輸出、diff、截圖與 artifact,方便 review 與事後追溯。
Why it matters
沒有 sandbox,AI 越會做事風險越高;有 sandbox,才有條件把它放進流程。
Sandbox 不是限制 AI,而是讓 AI 可以放心動手。企業真正需要的是可控執行、可審核紀錄、可回復狀態,而不是把整台電腦交給模型。
Claude Code 怎麼做 sandbox:approval、scope、trace、checkpoint
Approval flow
每個會動 fs / shell / network 的工具呼叫前,agent 先描述意圖;使用者按 yes / no / always-for-this-tool。
Scoped permission
權限不是全有全無:可以限到某個目錄、某個 binary、某個網域、某個 MCP server。
Trace
每一個 read / write / exec 都記在事件鏈裡,agent 動了什麼事後可審。
Checkpoint / resume
Sandbox 可以暫停、保存狀態、之後從 checkpoint 接續,不需要從頭跑。
這是「一家怎麼做」。Codex、其他 framework、自家平台都有自己的版本——重點是這四個能力存在與否,不是 implementation 細節。下一段看各家 plugin 怎麼把這些能力打包成可分發的 asset。
Production harness 至少要管六件事
拆任務
把模糊目標變成可執行步驟。
執行
調工具、讀寫檔案、產出 artifact。
調度工具
選 MCP、shell、file、browser 或專用 API。
管理 context
決定什麼進來、什麼壓縮、什麼丟掉。
錯誤恢復
失敗時能重試、回報、換工具或停止。
可恢復狀態
任務中斷後能從最近狀態繼續。
這六件事是 production agent 的最低檢查表。缺 planner 會亂做;缺 recovery 會卡住;缺 checkpoint,長任務一中斷就只能重來。
為什麼企業不能只把帳密交給 AI?
權限不要交給模型自己判斷。比較穩的做法是:人設定允許範圍,governance 決定可不可以,harness 只派必要動作,sandbox 執行,vault / proxy 在最後一刻使用 credential。
Context window 是金魚記憶;長任務需要外部 memory
Goldfish problem
Context window 滿了就忘。超過模型能力上限的長任務不能只靠塞 prompt。
Long task continuity
跨天、跨 session、跨打斷點的工作需要 checkpoint 與恢復機制。
Multi-user / multi-task
同一 agent 服務多人或多任務時,狀態不能混;需要 session 邊界。
Memory engineering 的核心問題不是「記住所有東西」,是「設計記得什麼、忘記什麼、何時召回」。下一頁拆三種 memory 類型。
Memory 的三種類型:episodic、semantic、procedural
事件、互動、決策的時序紀錄。回答「上次發生什麼」「為什麼當時做了那個決定」。
客戶上週的對話、上次部署的 incident 紀錄、PR review 的歷史。累積的知識、事實、領域常識。回答「這件事是什麼」「規則是什麼」。
公司退貨政策、命名 convention、API 規格、合約條款。學會的方法、流程、套路。回答「怎麼做」「步驟是什麼」。
「分析個案」的標準流程、「寫 PR description」的格式、「處理客訴」的腳本。Procedural memory 已經由前面講的 skill / workflow 解決。Episodic 跟 semantic 還需要明確的 storage layer——下一頁看實務做法。
Memory engineering 三策略:summarization、retrieval、checkpoint
Summarization
把舊互動壓縮成摘要 + 關鍵決策路徑。Context 保持輕量,但失去細節。
Retrieval
歷史與知識存到外部(vector DB、graph、SQL)。需要時才召回,不佔 context。
Checkpoint / Resume
長任務暫停、保存狀態、之後接續。Sandbox 跟 memory 一起決定能不能 recover。
三種策略通常一起用:summarization 處理 context 壓力、retrieval 補回需要的事實、checkpoint 讓長任務可恢復。Production agent 系統三種都要有。
Agent 進入企業,會被三個問題拷問:誰、什麼、做了什麼
Identity
Agent 代表誰行動?on behalf of which user、which team、which service account。每個 action 都要追得回主體。
Policy
能用哪些工具、讀哪些資料?allowlist / denylist / scope;不只是「能不能」,是「能到什麼程度」。
Audit
做了什麼、為什麼做、誰看過?事件鏈 + sign-off;事後可被 review、必要時可被回放。
Governance 不只是合規的需求。它決定 agent 能不能被法務、合規、稽核、管理層信任——這是 agent 從 pilot 走進 production 的真正閘門。
從「員工」到「他派的 agent」到「agent 用的工具」,權限要層層收斂
這是企業 IAM 模型套到 agent 的核心設計。否則任何 prompt injection 都可能讓 agent 用使用者的全權做事——這是 production agent 最大的安全風險之一。
Audit trail 的最低要求:紀錄什麼、留多久、誰能看、誰看不到
| 維度 | 要做的事 | 踩雷模式 |
|---|---|---|
| 紀錄什麼 | 每次 tool call、input、output 摘要、approval、failure / recovery、人為介入點。 | 只記成功不記失敗、只記結果不記輸入;事後追不回原因。 |
| 留多久 | 依產業規定:法務 7 年、金融 10 年、健康照護依 HIPAA、其他依公司 retention policy。 | 全部存永久(成本爆)或全部存 30 天(合規來查就出事)。 |
| 誰能看 | 使用者本人、合規部門、必要時稽核。存取本身也要被 log。 | 工程師可任意撈 audit log;GDPR、個資法問題立刻浮現。 |
| 不該被看到 | 原始 credentials、原始個資;需要 redaction、tokenization、hash 處理。 | audit log 直接存 raw token / SSN / 信用卡,外洩就是合規事件。 |
Trace 是工程觀測資料;audit 是治理證據——欄位、保存規則、存取控制都不一樣。Production agent 兩個都要有,且要能對齊。
Claude Code Plugin 是什麼?把 agent 能力做成可安裝、可版本化的套件
emba-famulus/ ├── .claude-plugin/plugin.json ├── .codex-plugin/plugin.json ├── skills/ │ └── biz-sme-management/SKILL.md ├── workflows/ │ └── case-study.md └── references/
Plugin 是 Claude Code 的能力分發格式
它不是單一 prompt,也不是完整 agent runtime;它把 skills、commands、agents、hooks、MCP servers、LSP、settings、bin tools 包成一個可安裝的 extension。
Claude Code plugin 的重點是把原本散在 .claude/、.mcp.json、hooks、agents、skills、commands 的設定包成可分享版本。安裝後,Claude Code harness 才會把這些資產註冊到實際執行循環。
Claude Code plugin 裡面可以包哪些東西?每個元件都接到不同 runtime hook
| Plugin component | 預設位置 | 接到 Claude Code harness 的哪一段 |
|---|---|---|
| Manifest | .claude-plugin/plugin.json | 定義 name、description、version、author、路徑覆寫與 plugin metadata;也提供 namespacing。 |
| Skills | skills/<name>/SKILL.md | 進入 skill discovery 與 model-invoked routing;被任務觸發後載入流程、gotchas、references。 |
| Commands | commands/*.md | 提供使用者可明確呼叫的 slash command;適合固定入口與可傳參數任務。 |
| Agents | agents/*.md | 註冊 custom subagent:獨立 context、系統指令、工具權限、模型與 delegation description。 |
| Hooks | hooks/hooks.json | 接進 lifecycle events,例如 PreToolUse、PostToolUse、Stop、SubagentStart,用於 policy、automation、validation。 |
| MCP servers | .mcp.json | 把外部 tools/resources/prompts 註冊到 tool interface,讓 harness 在 tool routing 時可發現與呼叫。 |
| Settings / bin | settings.json / bin/ | 設定預設 agent 或 status line;把 plugin executable 加進 Bash PATH,支援本地執行。 |
明顯的做法:把一個職能場景包成 plugin,而不是讓使用者每次重新說明
asgard-ecommerce-operator/
├── .claude-plugin/plugin.json
├── skills/
│ ├── tw-ecom-analytics-ga4/SKILL.md
│ ├── tw-ecom-invoice-universalec/SKILL.md
│ └── mkt-ab-testing/SKILL.md
├── agents/
│ └── ops-analyst.md
├── hooks/
│ └── hooks.json
├── .mcp.json
└── bin/
└── export-weekly-report把 domain workflow 變成可安裝能力
安裝後,使用者可以要求「分析本週電商營運狀況」。harness 會載入電商與 GA4 skills、呼叫 GA4/Shopline MCP、必要時交給 ops-analyst subagent,最後由 hook 檢查輸出是否含資料來源與指標定義。
Plugin 不是裝飾。這個範例把一個職能場景的知識、資料連線、執行工具、審核規則與預設 agent 組合起來,讓非技術使用者不用每次重新教 agent 背景。
職能 plugin 的元件拆解:每個元件都對應一種 harness responsibility
| 元件 | 做什麼 | 為什麼要包進 plugin |
|---|---|---|
| Skills | 定義分析框架、指標、gotchas、報告格式。 | 避免每次從零教 agent 怎麼分析,也讓方法論可以被版本控管。 |
| MCP | 連接 GA4、Shopline、發票、客服或庫存系統。 | 外部資料與 credential boundary 不放進 prompt,讓工具 schema 與授權由執行層管理。 |
| Agents | 把常見工作交給固定角色,例如 ops analyst、security reviewer、data checker。 | 把 context、tool access、model choice 與工作邊界固定下來,減少每次臨場指定。 |
| Hooks | 在工具前後或輸出前檢查來源、格式、風險字眼、測試結果。 | 把 review gate 從人工提醒變成 lifecycle control,尤其適合 release、資料、合規與安全檢查。 |
| bin / scripts | 提供 plugin 專用 executable、轉檔器、匯出器或驗證器。 | 把重複又容易算錯的步驟做成可執行工具,讓 agent 負責決策與整合。 |
Claude Code 如何把 plugin 組合成 harness 可用的能力?
因此「做 plugin」不是只放一堆 prompt,而是在定義 Claude Code harness 可以載入哪些能力、什麼時候觸發、哪些工具可用、哪些事件要自動檢查,以及成果如何被人 review。
Skill、Workflow、MCP、Plugin 不是同一種東西,但會被同一個 harness 組合
| 層級 | 它回答的問題 | 典型內容 | 例子 |
|---|---|---|---|
| Skill | 這類任務應該怎麼判斷與交付? | 方法論、流程、output contract、gotchas、references、scripts。 | meta-structured-problem、mkt-ab-testing |
| Workflow | 這個任務要走哪些步驟? | 任務管線、角色分工、交付順序、review gate。 | case-study、industry-analysis、executive-pitch |
| MCP Server | agent 要如何安全呼叫外部能力? | tool schema、resource、prompt、auth boundary、error contract。 | 實價登錄、Shopline、內部 CRM API |
| Plugin | 這組能力如何被安裝、版本化、分享? | manifest、skills、commands、agents、hooks、MCP config、settings。 | Claude Code plugin、Codex plugin、Yggdrasil solution bundle |
這些東西如何被 harness 使用?從任務進來到產物出去
任務進來後,harness 先做 task classification,再選 plugin / workflow,按需載入 skill,選擇 MCP 或 CLI executor,最後在 sandbox 裡執行並保存 artifact、log 與 checkpoint。
Claude Code / Codex 都在把 agent 變成可工作的工作台
從 terminal / IDE / web 進入 repo 與工作流程
它把 repo context、MCP、CLAUDE.md、skills、hooks、plugins、git 與審核流程接成 coding agent runtime。
從 CLI、cloud task、desktop app 延伸到一般工作
它把本機讀寫執行、雲端 sandbox、browser、plugins、skills、MCP、memory 與 automation 放進同一個工作台。
這不是單一廠商的行銷詞,而是產品形態正在收斂:agent 不只是模型,而是包含 repo / app context、tool interface、sandbox、approval、trace、memory、plugin / skill 的工作環境。
比較之前先分層:不要把 runtime、plugin、framework 放在同一排
Claude Code / Codex
使用者直接拿來工作的 agent runtime / workbench,負責 repo context、tools、sandbox、approval、trace 與交付。
Claude Code Plugin
不是完整 runtime,而是把 skills、commands、agents、hooks、MCP servers、settings、bin tools 包進既有 runtime。
OpenClaw / Hermes
更接近自架 autonomous agent framework:強調常駐、記憶、多工具、多平台或可自託管 execution。
Asgard
不是只提供單一 agent,而是把 workflow、insight、execution、open-source assets 與 governance 產品化。
Claude Code、Codex、OpenClaw、Hermes:定位可以用四個維度看
| 工具 / 框架 | 主要定位 | 能力包裝 | 執行環境 | 適合場景 |
|---|---|---|---|---|
| Claude Code | coding agent runtime / workbench | CLAUDE.md、skills、commands、agents、hooks、plugins、MCP | 本機 terminal / IDE / web;與 repo、git、tool use 深度整合 | 軟體專案、repo 理解、修 bug、寫測試、PR / release workflow |
| Codex | OpenAI coding agent 與多工作 app | AGENTS.md、skills、plugins、MCP、app integrations、automations | 本機 CLI、desktop app、cloud sandbox、browser / computer use | 多人/多 agent 任務、程式與文件工作、跨工具資料整理與長任務 |
| OpenClaw | open-source autonomous agent framework | 任務、工具、記憶、常駐 agent 能力 | 以自架或本機 autonomous agent 執行為主 | 想研究或自建長時間自主 agent loop、工具調度與常駐任務的人 |
| Hermes Agent | open-source autonomous agent with persistent memory | skills system、auto-created skills、gateway、browser / code execution | local terminal、Docker、SSH remote、cloud / HPC backends | 自託管、跨訊息平台、持久記憶、多模型與可攜 skill 的 agent 實驗 |
這張表的目的不是選冠軍,而是先定位——「產品工作台、extension package、autonomous framework、enterprise platform」是不同層級。先把分類清楚,後面比較才不會混淆。
RPA 還是 Agent?不是取代,是分工
| 維度 | RPA | Agent |
|---|---|---|
| 適合任務 | 結構化、規則明確、可錄製成腳本的高頻流程 | 半結構化、需要語意理解、跨系統推理的任務 |
| 變更成本 | UI 改一點就壞;維護成本隨著系統迭代上升 | 用語意理解輸入,較有彈性;prompt / skill 可調 |
| 上線速度 | 流程錄製 + 測試,週級 | 寫 task brief,可日級到時級 |
| 治理面 | 流程是白紙黑字;錯了可單步追 | 需要 trace、approval、human review;governance 較複雜 |
| 失敗模式 | 資料格式異常、UI 變動就斷 | 判斷錯誤、context 不足、tool selection 錯 |
| 搭配方式 | 前置:高頻、規則明確的部分照舊跑 | 後置:用 agent 處理需要判斷的尾段;agent 的結果回饋給 RPA |
RPA 不會被 agent 取代;它擅長的高頻穩態工作仍會繼續跑。Agent 補上 RPA 做不到的地方——需要判斷、跨系統推理、處理意外輸入。混合架構(RPA + agent)會是大多數企業的下一步。
實務選型:先看你要解決哪一層問題
個人與團隊要立刻開始交辦工作
從 Claude Code 或 Codex 這種 workbench 開始,因為它們已經把 repo context、tools、sandbox、approval、artifact review 做成可用介面。
要研究或自建 autonomous agent runtime
OpenClaw、Hermes 這類 framework 更適合看 agent loop、memory、tool orchestration、常駐服務、gateway 與 execution backend。
要把方法論和工具分享給團隊
用 Skill / Plugin / MCP / workflow,把工作方法、工具連線、審核規則與輸出格式做成可安裝、可版本化資產。
要進企業流程、權限與治理
需要平台層處理身份、資料權限、審核、部署、觀測、成本、流程整合與跨部門 adoption,這就是後面 Asgard 要回答的問題。
實作路線:從委派工作,到查資料、套方法、可審核執行
委派工作
用 Codex / Claude Code 建立任務 brief、先規劃、再產出。
外部工具
用 MCP 查實價登錄,證明 agent 不是用模型記憶猜資料。
專業方法
用 emba-famulus 展示 plugin、workflow、skills 如何載入。
可控執行
用 sandbox trace 看事件鏈、工具執行、artifact 與 review surface。
四個 demo 是同一條軸線——從「把工作說清楚」到「讓 AI 接外部資料」、「把方法包成可重用資產」,最後加上 sandbox 與 trace 才能交給組織用。
Demo 0:Codex / Claude Code 起手式,先讓 agent 理解工作現場
請先不要產出最終答案。 請你先做三件事: 1. 掃描目前資料夾,理解有哪些素材 2. 用 5 句話說明你理解的任務 3. 提出你會怎麼完成,包含風險與需要我確認的地方 等我說「開始」後,再進入產出。
這段不是看答案,而是看它有沒有建立正確工作模型
成功標準是 agent 能說清楚目標、素材、限制、輸出格式、風險與下一步。它如果一開始就產出,很可能只是把任務當一般問答。
Demo 0 對應的是 task delegation。先要求 agent 建立 task understanding 與 execution plan,再允許產出,可以降低錯誤方向的 sunk cost。
看什麼:不是看文筆,而是看 plan 是否可驗收
| 畫面上看什麼 | 代表什麼 | 你要怎麼介入 |
|---|---|---|
| 它是否掃描正確資料夾 | context source 是否正確 | 資料源錯就立刻停,不要讓它繼續產出。 |
| 它是否重述任務與受眾 | goal / audience alignment | 如果受眾、語氣、用途錯,先修 brief。 |
| 它是否列出風險與需要確認處 | agent 是否知道自己的不確定性 | 補上限制、不要碰的範圍、可用來源。 |
| 它是否提出可追蹤步驟 | planner 是否能被 review | 要求它先列 TODO,再開始讀檔、查證、產出。 |
說明:一次任務完成後,要把方法沉澱成 reusable workflow
接下來的 Demo 1 會往下一層走:當任務需要真實外部資料時,不能只靠 prompt;需要 MCP 或其他 tool interface。
MCP 實戰:台灣不動產實價登錄,讓 agent 用工具查真實資料
任務: 幫我查台北市信義區租賃資料, 確認 agent 是透過 MCP 工具取得資料。 執行路徑: 1. 啟動 mcp-tw-lvr server 2. 檢查 MCP tools 是否註冊 3. 呼叫 query_real_price_tool 4. 帶入 city / district / transaction_type 5. 觀察 records returned 6. 把 tool result 摘要成人可讀結論
AI 不猜市場資料,而是呼叫受控的在地資料工具
Demo 1 的重點不是房價,而是工具使用流程:自然語言需求要被轉成 structured parameters,tool result 要能追溯,最後再由模型整理成人可讀分析。
看什麼:MCP demo 要看工具選擇、參數映射、回傳結果與資料限制
| 觀察點 | 畫面上看到 | 技術含義 |
|---|---|---|
| Tool selection | query_real_price_tool 被呼叫 | agent 透過 MCP client 呼叫 server,不是自行生成資料。 |
| Input mapping | 縣市、行政區、交易類型被帶入 | 自然語言需求被轉成 typed parameters。 |
| Live result | 回傳資料筆數與摘要 | tool result 可能很大,harness 要決定摘要、取樣、保存 artifact 或限制 context。 |
| Interpretation | agent 說明資料範圍與限制 | model 負責解釋資料,不負責捏造資料來源。 |
MCP live query:真的打到實價登錄資料源
 71 / 101
71 / 101MCP server 測試畫面:connector 要能工程驗收
 72 / 101
72 / 101說明:MCP server 不是 prompt,它要像一般軟體一樣能被測試
Server startup
確認 server 能在 demo 環境啟動,不依賴講者機器上的隱性狀態。
Tool discovery
確認 tools/list 看得到預期工具,工具名稱與 schema 沒有漂移。
Tool call result
確認 tools/call 回傳可解析結果,錯誤訊息能讓 agent 修正參數。
# validation checklist uv run pytest claude /mcp claude mcp get <server-name> # 要確認: # 1. server 起得來 # 2. tools/list 看得到工具 # 3. tools/call 回傳可解析結果73 / 101
下一個例子:工具能查資料,但專業判斷要靠 workflow 與 skill 包裝
外部資料
MCP 解決 agent 如何安全、結構化、可追溯地呼叫資料源或服務。
專業方法
知道資料還不夠。agent 還需要知道用什麼分析框架、怎麼下判斷、交付格式是什麼。
Plugin / Skill
用 emba-famulus 看 workflow 偵測、skill 載入與 output contract。
emba-famulus:用開源 plugin 組出 EMBA 商管 agent
emba-famulus/
├── .claude-plugin/plugin.json
├── .codex-plugin/plugin.json
├── skills/
│ ├── biz-sme-management/
│ ├── biz-corporate-governance/
│ └── fin-m-and-a/
└── workflows/
├── case-study.md
├── industry-analysis.md
└── executive-pitch.md任務: 我要寫一份家族企業接班的個案分析作業。 主題:一家台灣中型製造業,二代準備接班, 一代想做治理結構調整,也可能引入外部資金。 請產出結構化報告。
這裡不是從零寫 agent,而是把既有 harness、plugin、skills、workflow 組合起來。商管框架、案例分析流程與輸出格式不必每次重寫。
看什麼:Plugin demo 要看 task classification、workflow、skill 與 output contract
Plugin routing:workflow 與 skills 被組成可攜資產
 77 / 101
77 / 101說明:Plugin 是分發包,Workflow 是流程,Skill 是專業方法
| 層 | 作用 | 為什麼重要 |
|---|---|---|
| Plugin | 分發 skills、workflows、references、MCP config | 讓同一套 agent 能力可以安裝、版本化與分享。 |
| Workflow | 定義任務 pipeline 與中間產物 | 同類任務不用每次重新規劃。 |
| Skill | 補充專業判斷、框架、輸出格式與 gotchas | 讓 model 不只是泛泛回答,而是套用特定方法論。 |
| Harness | 決定何時載入、何時呼叫工具、何時要求人 review | 把 plugin asset 接進真正的工作生命週期。 |
下一個例子:agent 開始動手後,企業要看的不是答案,而是事件鏈
知識可重用
Plugin / workflow / skill 讓專業方法成為資產,不再只存在一次對話中。
執行可治理
當 agent 會讀檔、跑指令、改檔、產出 artifact,企業需要知道它做了什麼。
Sandbox trace
看 file reads、commands、diff、artifacts、failure / recovery。
Sandbox trace:把 agent 的工作過程變成可限制、可審核、可交接的事件鏈
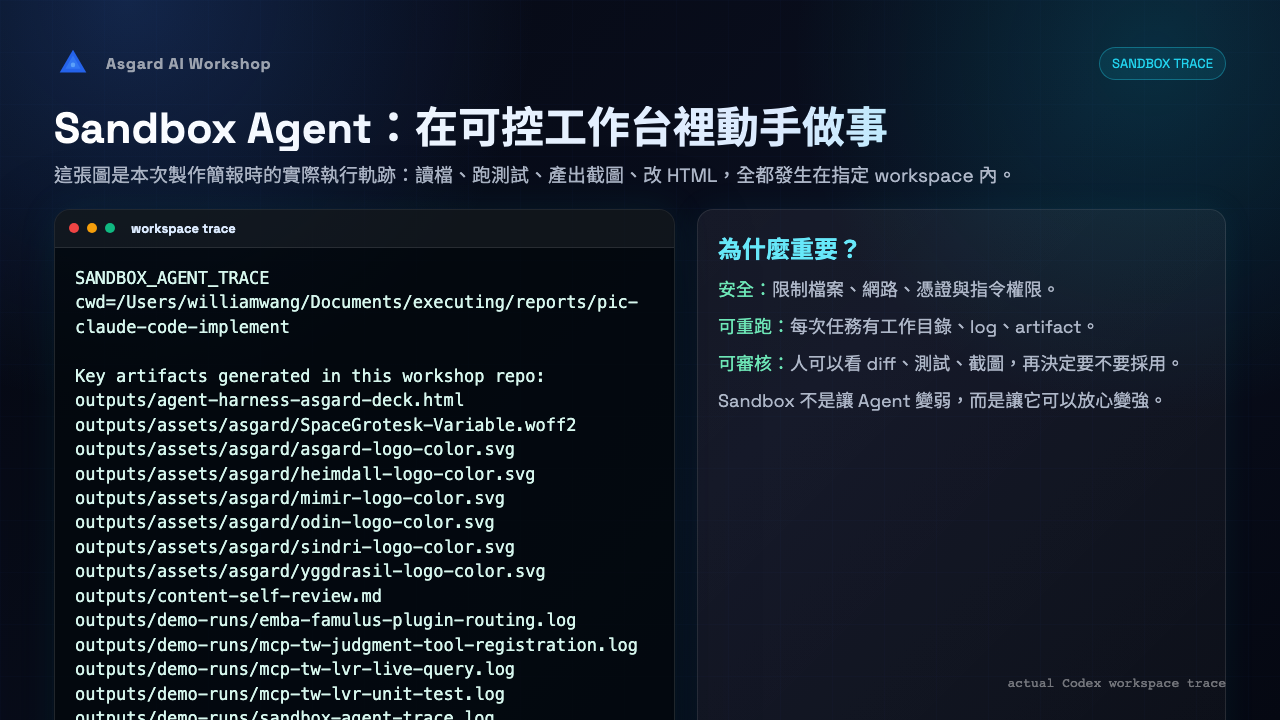
Demo 3 不是新增一個案例,而是把前面所有案例放回 production requirement:agent 只要能動手,就需要 sandbox、permission、trace 與 recovery。
Sandbox trace:畫面要看 agent 實際做了哪些事
 81 / 101
81 / 101看什麼:不是只看最後答案,而是看每個動作是否可審核
| Trace 元素 | 代表什麼 | 企業驗收問題 |
|---|---|---|
| File reads | agent 讀了哪些資料與素材 | 是否讀到正確資料源?是否碰到不該讀的檔案? |
| Commands / tests | agent 跑了哪些 shell、測試、轉檔或瀏覽器自動化 | 指令是否可重現?是否有 timeout / permission policy? |
| Diff / artifacts | agent 改了哪些檔、產出哪些圖片、報告、簡報或 log | 交付物是否能 review?中間產物是否可追溯? |
| Failures / recovery | 錯誤、重試、替代方案與人工介入點 | 失敗後是否有恢復策略,還是只能重新開始? |
說明:三個 demo 合起來,就是 production agent 的最小閉環
| Demo | 證明的能力 | 對應的 harness responsibility |
|---|---|---|
| Demo 0:委派工作 | 把模糊需求轉成可執行 plan | task understanding、planning、human review。 |
| Demo 1:MCP 工具 | 把外部資料源包成可呼叫、可驗證的工具 | tool routing、schema、credential boundary、result handling。 |
| Demo 2:Plugin / Skill | 把專業方法與 workflow 做成可重用資產 | knowledge routing、workflow selection、output contract。 |
| Demo 3:Sandbox trace | 讓 agent 執行過程可限制、可追溯、可驗收 | sandbox、permission、artifact、trace、recovery。 |
如果六層是架構,企業需要的是可使用的平台
這頁是從技術架構轉到產品價值:部門要效率,IT 要可控,管理層要看得到責任與成效。平台要同時回答三方問題。
Asgard 的產品生態系:企業 AI 閉環平台加開源資產層
Asgard
Enterprise AI Enablement Platform。從資料洞察到自動化執行,協助企業把 AI 嵌入真實流程。
Yggdrasil
以 MIT open-source 模式,把 MCP Servers、Skills、Solution Bundles 做成可攜資產,降低 adoption friction。
產品定位:Asgard 承接 enterprise deployment、workflow、insight、execution 與治理;Yggdrasil 承接開源 MCP、skills、solution bundles 的分發與驗證。
Asgard 三大核心模組:Workflow、Insight、Execution
Asgard Studio
IT / MIS 導向的 no-code AI 工作流編排。支援多種處理節點、multi-agent、一鍵發布。
Data Insight
管理層 / 策略單位導向的 AI 決策核心。自然語言問數據、自動 SQL、Dashboard 與 Semantic Layer。
Agent Hub
營運 / 業務單位導向的 AI 執行引擎。支援 channels、collections、memory 與企業系統串接。
Odin 負責把流程做出來,Mimir 負責讓管理者問數據與看洞察,Sindri 負責讓 agent 在業務與營運場景中執行。三者加起來,才是企業 AI 閉環。
六層架構如何對應到 Asgard / Yggdrasil
Yggdrasil 偏工具與知識資產;Odin / Sindri 偏 harness 與執行;Forseti 對應企業治理;Midgard 對應地端 / 私有雲部署。Sandbox 是 Odin 內建的執行底層,不另外作為產品線。Tools 層除了 Yggdrasil,也兼容市面上各種 MCP / A2A / CLI 工具。
Yggdrasil:把工具、知識、solution bundles 做成可攜資產
MCP Servers
連接資料源、API、內外部系統。
Skills
封裝方法論、判斷準則、常見陷阱。
Solution Bundles
把特定任務的 MCP、skills、workflow 打包成可使用方案。
Workflows
用 markdown 描述任務類型的 pipeline。
開源模式不是把產品免費送掉,而是把 adoption friction 拿掉。企業可以先從公開工具與方法開始試,再逐步放到自己的治理與部署環境。
Token 不是免費的:每個任務跑一次要多少錢?
Token 經濟學
每個任務 = input × $X + output × $Y + tool call × $Z。長任務 + retry + 多輪 dialogue 容易把成本帶到單筆數十美元。
Prompt caching
System prompt、skill body、reference docs 不會每次變動 → cache 起來。Anthropic / OpenAI 都支援,可省 50-80% input cost。
Model tiering
Cheap model 做 routing / 簡單判斷,expensive model 只跑核心 reasoning。比全用旗艦模型省 60-80%。
Cost monitoring
每個任務 → budget upper bound;超過自動停。Cost per successful task 應該是常駐 dashboard 指標。
成本失控是「發布後三個月才發現」最常見的問題。設計階段就要有 cost 模型,把它跟 quality metrics 一起看。
怎麼知道 agent 在做事?五個 production quality 指標
| 指標 | 在量什麼 | 失控訊號 |
|---|---|---|
| Task success rate | 任務完成比例(agent 自評 + 使用者驗收) | 突然下降 = workflow 或 tool 改版踩到雷 |
| Time to completion | 平均單次完成時間 | 突然變長 = retry 暴增、tool 失靈、或新任務類型沒對應 skill |
| Human intervention rate | 被人工打斷、修正、覆寫的比例 | 高 = agent 沒抓到正確規則或 context 不足 |
| Cost per successful task | 完成一次任務的平均 token / API cost | 降不下來 = retry 過多、prompt 過長、缺 caching |
| User satisfaction / retention | 使用者實際留下來用的比例(7d / 30d) | 上線後熱度衰退 = 解決不了真實問題 |
五個指標一起看才有意義。只看 success rate 會掩蓋成本爆走;只看 cost 會錯過品質下滑。Production agent 的 dashboard 至少要這五欄。
Trace 是單次紀錄;Observability 是跨 run 的指標 + 警報
Trace
一次 run 的完整事件鏈:讀檔、tool call、結果、決策路徑。Demo 3 看到的就是 trace。
Aggregation
跨 run 的指標彙總:每天 / 每週的 success rate、latency、cost 趨勢。
Alerting
成本突然飆、錯誤率突增、某 tool 全部失效 → 自動通知。不能等使用者抱怨才知道。
Regression test
新版 skill / 新 model 上線前,跑一組 test set,比較跟舊版的差異。避免改一處壞十處。
很多企業 agent 跑了半年才發現某類任務一直失敗,因為沒有 aggregation 指標。Regression test 與 alerting 是 agent 從「能跑」到「能維運」的分水嶺。
Agent 不該負責的事:高風險決策、real-time SLA、對抗輸入
高風險單次決策
醫療診斷、財務交易、人事決定——必須 human-in-the-loop。Agent 可以做 recommendation 與資料整理,但拍板要回到人。
Sub-second SLA
需要毫秒級回應的場景(廣告競價、即時風控)— agent loop 的延遲太高。用 deterministic 系統,agent 跑後台分析。
對抗性輸入
Fraud detection、anti-spam、安全攻防——對手會 prompt injection。權限要極小化、sandbox 要嚴、output 要驗。
強合規 / 可解釋性場景
金融、醫療、法律部分流程要求決策可追溯、可解釋。Agent 黑盒問題在這裡會暴露。
列這個不是要勸退;是建立清楚界線。誤把 agent 用在錯的場景,比沒用 agent 還慘——錯誤被自動化放大、責任歸屬不清、合規踩雷。
現場練習:把自己的工作改寫成 agent 任務
| 步驟 | 你要填什麼 | 例子 |
|---|---|---|
| 1 | 一個常重複、可驗收的工作 | 整理客戶週報、產業摘要、會議 follow-up |
| 2 | 需要哪些資料 | 文件、表格、CRM、網站、聊天紀錄 |
| 3 | 成功長什麼樣 | 一頁摘要、10 張投影片、風險清單、待辦清單 |
| 4 | 不能做什麼 | 不能寄信、不能改資料、不能使用未核准資訊 |
| 5 | 如何留下紀錄 | 列來源、列假設、列決策與待確認事項 |
適合改寫成 agent task 的工作具備三個特徵:重複發生、資料來源相對固定、成果可驗收。範圍越小,越容易建立可重複的 workflow 與 skill。
從一個人用,到全公司用:四階段 adoption ladder
一個 use case 跑通
5-10 人沉澱 skill
跨部門平台 + 治理
像 Slack 一樣基礎設施
從第 4 階段開始
從第 1 階段先跑通
Agent 的學習成本不在工具,在「組織知道哪些工作該交給 agent」。先用個人 use case 累積素材,第 2 階段才有東西沉澱成 skill library,第 3 階段才有規則可制定治理政策。
上線前,用這張表檢查你的 agent
| 檢查項 | 問題 | 不合格訊號 |
|---|---|---|
| Model | 能不能換 model 而不重寫流程? | 狀態藏在 prompt 或 provider 特定格式 |
| Tools | 工具描述、權限、錯誤是否可被 agent 理解? | 工具會被誤用,錯誤後無限重試 |
| Harness | 是否有 planning、recovery、checkpoint? | 跑久就失控,斷線就重來 |
| Sandbox | credentials 是否離開執行環境? | 模型生成程式能讀到敏感 token |
| Governance | 每次決策能不能追溯? | 出事後只剩聊天紀錄,沒有事件鏈 |
這張是上線前的最低門檻。只要有一項回答不出來,就先不要把它叫 production agent;先把流程、權限、紀錄與恢復能力補齊。
12-24 個月內,agent 架構會往哪走?
Model-native harness
模型廠商把更多 harness 能力做進模型本身(OpenAI Managed Agents、Anthropic Claude Code 都在這條線上)。Application 層 harness 會更薄,但仍存在。
Persistent agents
Agent 從「跑一次任務」變「常駐角色」:可被 @-mention、可 schedule、有自己的 memory 與 inbox。不再是 chat,是同事。
Agent marketplaces
類似 App Store 的 plugin / skill / agent 流通市場逐漸成型。可信賴度、版本治理、付費模型都會跟上。
Governance standards
類似 PCI-DSS、SOC2 的 agent 合規標準會出現;保險與法規會跟著要求。早期投資治理的組織會有 compliance 優勢。
別賭單一工具能贏到底;可以賭「production agent 需要 6 層」這個架構不會變。把組織能力建立在 6 層各層的判準上,工具換了不會白做。
一句話總結
今天開始
用 Codex / Claude Code,把一個重複工作改寫成任務。
下一步
把成功做法沉澱成 workflow 或 skill。
企業放大
用 Asgard / Yggdrasil,把工具、知識、權限和治理接起來。
工具名稱會改變,但成熟度判準不變:能否在可控流程中規劃、執行、恢復、紀錄與交付可驗收成果。
帶一個工作回去,把它包成 agent asset
重複、耗時、可驗收
目標、資料、限制
Codex / Claude Code
workflow / skill
CLI 先行,MCP 升級
sandbox / log / review
個人
用 Codex / Claude Code 做研究、整理、寫作、簡報、程式與自動化。
團隊
把做得好的流程變成 skill / workflow,讓同事可以重複使用。
企業
用 Asgard / Yggdrasil 把資產、工具、權限與治理接起來。
落地順序:先選一個重複工作,寫 task brief,跑一次 agent loop,review 結果,再沉澱 workflow / skill;當任務需要共享、權限或 audit 時,再接 MCP 與治理層。